李军 李世昌

摘 要:针对中期或短期电力负荷预测,提出一种基于稀疏表示的特征提取建模方法。为构建预测模型,将历史电力负荷等数据构成具有时延的输入—输出数据对,将时延输入数据向量作为初始字典,采用K均值—奇异值分解(K-SVD)算法将其进行稀疏分解与变换至稀疏域以得到学习后的字典。进一步,由正交匹配追踪(OMP)算法获取相应的稀疏编码向量,再将该向量作为核极限学习机(KELM)的输入来构建全局回归模型。为了验证该方法的有效性,将所提出的方法用于不同地区的中期或短期电力负荷预测中,在同等条件下还与单一KELM、支持向量机(SVM)、极限学习机(ELM)方法以及非字典学习的其他稀疏表示建模方法进行了比较。实验结果表明,不同的稀疏表示建模方法均能取得很好的预测效果,其中所提方法具有更好的預测效果,显示出其有效性。
关键词:负荷预测;稀疏表示;特征提取; K均值—奇异值分解; 正交匹配追踪;核极限学习机
DOI:10.15938/j.emc.2020.09.017
中图分类号:TM 715
文献标志码:A
文章编号:1007-449X(2020)09-0156-09
Application of sparse representation method based on K-SVD-OMP in electricity load forecasting
LI Jun, LI Shi-chang
(School of Automation and Electrical Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China)
Abstract:
For mid-term or short-term electricity load forecasting, a feature extraction modeling method based on sparse representation is proposed. The historical power load data were composed to the time-lagged input-output data pairs to build the forecasting model, using the time-lagged input data vectors as the initial dictionary, which were sparsely decomposed and transformed into the sparse domain by K-means singular value decomposition (K-SVD) algorithm to obtain the dictionary after learning. Further, the corresponding sparse coding vectors were obtained by orthogonal matching pursuit (OMP) algorithm, and then the sparse vectors are then used as the input vectors of the extreme learning machine with kernel (KELM) to build a global regression model. In order to verify the effectiveness of the employed method, it was applied to mid-term and short-term electric load forecasting instances in different areas. Compared with single KELM, support vector machine(SVM), extreme learning machine(ELM) method as well as other forecasting methods using sparse representation with non-dictionary learning under the same conditions, experimental results show that the forecasting methods based on sparse representation algorithm achieve good forecasting results, and the methods proposed significantly improve the accuracy of load forecasting and show their effectiveness.
Keywords:load forecasting; sparse representation; feature extraction; K-means singular value decomposition; orthogonal matching pursuit; extreme learning machine with kernel
0 引 言
中、短期电力负荷预测作为电力系统规划和运营的重要组成部分,对电力部门制定发电计划、设备检修计划、电价等提供了重要的依据。因此,构建稳定、准确的中、短期电力负荷预测模型对智能电网的运行调度与发展规划有着重要意义[1-2]。
在电力负荷预测中,常见的线性或多重回归法、自回归积分滑动平均[3] (autoregressive integrated moving average,ARIMA)方法等,在精度方面往往不能满足实际需求。更先进的一类计算智能方法,如神经网络[4]、模糊逻辑系统[5]、支持向量机[6] (support vector machine,SVM)、相关向量机[7] (relevance vector machine,RVM)等,具有很强的非线性逼近能力,目前已经在中、短期负荷预测中取得了成功应用,如文献[7]给出了基于多种组合核函数构成的RVM方法,应用于中期电力负荷预测中并取得了较好的实验效果。
极限学习机[8] (extreme learning machine,ELM)是由Huang等人提出的一种基于单隐层的前馈神经网络快速学习算法,具有学习速度快,泛化性能好的优点。在ELM的基础上,核极限学习机(extreme learning machine with kernel,KELM)采用核函数替代ELM中的未知隐含层节点函数,并通过引入正则化参数,求解结果更稳定且具有更好的泛化能力。文献[9]给出了一类基于进化策略的优化KELM方法,并成功应用于风电功率预测中。文献[10]给出一种基于经验模态分解的KELM预测方法,成功应用于短期电力负荷预测中。文献[11]提出了一种基于KELM的微电网短期负荷预测方法,建立了包含离线参数寻优与在线负荷预测的预测模型,该方法能获得较高的预测准确度。
另一方面,稀疏表示作为一种特征提取手段,首先在图像领域中得到广泛应用[12-13]。稀疏表示方法包括稀疏编码及字典学习,稀疏编码是由少数基向量加权和的形式对信号进行处理,提取隐含的实质性信息。文献[14]利用网络拓扑,借鉴半监督学习的框架,提出一种字典学习算法,将其成功应用于网络动态过程预测中。文献[15]则给出一种基于K均值—奇异值分解(K-means singular value decomposition,K-SVD)的字典学习算法,将其成功用于金融领域时间序列的股票收益预测中。
此外,主元分析(principal components analysis,PCA)或核主元分析(kernel principal components analysis,KPCA)方法作为一种特征预处理手段,也能很好地挖掘数据的内在特征,从而进一步增强模型的推广性。文献[16]提出了一种基于PCA算法进行特征提取的短期负荷预测模型,取得了很好的实验效果。文献[17]提出一种KPCA优化回声状态网络的网络流量预测方法,仿真对比实验表明了该方法预测结果的有效性。与此相似,同样可以将稀疏表示作为特征提取的主要手段应用于预测领域,虽然形如PCA方法也可得到一组完备的基向量,但有所区別的是,稀疏表示算法可得到一组超完备基向量来表示输入向量,其基向量通常比输入向量的维数要高,因此,能更有效地找出隐含于输入数据中的内在结构与模式。文献[18]给出了基于贪婪学习策略的稀疏编码算法—正交匹配追踪(orthogonal matching pursuit,OMP)算法并用于信号恢复中,与基寻踪(basis pursuit,BP)算法相比更快且更易于实现。文献[19]给出了针对信号稀疏表示的过完备字典进行训练的基于K-SVD的高效字典学习算法及其实现。
鉴于稀疏表示算法在特征提取建模中的优点,本文提出一种基于字典学习的K-SVD-OMP稀疏表示算法,与KELM方法结合,构成一种全局预测模型。将所提方法应用于不同地区的电力负荷预测中,在同等条件下,还与单一KELM等预测方法以及基于非字典学习的稀疏表示特征提取建模方法进行对比,验证所提方法在电力负荷预测中的有效性。
1 信号的稀疏表示
稀疏表示是对超完备字典中基向量进行线性组合,以紧凑的方式表示原信号,原信号则可通过被选择的权值非零的字典基向量表示,且大多数字典基向量的权值为零,信号向量x∈Rm的稀疏表示为
x=Φα。(1)
式中:Φ={1,2,…,K}∈Rm×K为字典矩阵,基向量i是字典Φ中的原子;α∈RK为稀疏向量。
针对式(1),通过l0范数优化问题的求解,可获得α∈RK的近似逼近,即
minα‖α‖0 s.t.‖Φα-x‖22≤δ。(2)
式中信号重构误差δ≥0。
限制α中非零系数的数目,可将式(2)变形为M-稀疏优化问题,即
minα‖Φα-x‖22 s.t.‖α‖0≤M。(3)
式中M为稀疏度,即α中的非零系数的数目。
将式(2)引入拉格朗日乘子λ可变换为
minα12‖Φα-x‖22+λ‖α‖0。
(4)
式中λ>0。
对式(2)~式(4)的本质求解是一个非确定性多项式(non-deterministic polynomial, NP)难题,求解这类问题可用松弛算法或贪婪算法,使用松弛算法时,假设α的先验分布服从Laplacian分布[20],可使信号的表示稀疏化,即
式(8)为式(4)的l1范数表达形式。式(4)的松弛算法求解就是将l0范数松弛到l1范数进行求解,l1范数是l0范数的最优凸近似,且满足解的稀疏性。对式(8)的求解可通过套索(least absolute shrinkage and selection operator,LASSO)算法求解[21]完成。具体实现时,通过调用凸优化(convex optimization, CVX)工具箱软件[22]完成式(8)的优化问题求解。
2 K-SVD-OMP算法
在稀疏表示中,不同的字典对于信号的重构效果不同,常用的字典有小波字典、离散余弦变换 (discrete cosine transform, DCT)字典、Gabor字典等。为更好地针对不同信号的稀疏表示,本文首先考虑性能较优的基于K-SVD的字典学习算法,以获取基于经验数据学习的具有自适应性且性能较优的紧凑字典,在此基础上进一步应用基于OMP的稀疏编码算法,获取数据的最佳稀疏编码向量。
2.1 K-SVD算法
K-SVD算法是K-均值算法的一种扩展,K-均值算法的目标是根据近邻分配原则,通过求解一个包含K个代码的码本,对数据集进行表示。考虑有限的数据向量xi取为标准基向量,K-均值算法的目标函数为
minC,X‖X-CA‖2F s.t. i,xi=ek。(9)
式中:X={xi}Ni=i∈Rm×N为数据集;C=[c1,c2,…,cK]为码本矩阵,其列向量ci为码本向量;标准基向量ek表示其第k个位置的元素为1,其余为0。
基于矢量量化的K-均值算法步骤如下:
Step 1:初始化码本C(0)∈Rm×K,令J=1;
Step 2:稀疏编码阶段:将数据集X分为K个子集
(R(J-1)1,R(J-1)2,…,R(J-1)K),
满足R(J-1)k={i|l≠k,‖xi-c(J-1)k‖2<‖xi-c(J-1)l‖2};
Step 3:码本更新策略:对子集C(J-1)中的每列k进行更新,即更新c(J)k=1|Rk|∑i∈R(J-1)kxi;
Step 4:令J=J+1;迭代计算Step2~Step4,直至满足重构误差。
K-SVD算法在K-均值算法基础上对K个不同子集进行奇异值分解(singular value decomposition,SVD),构造出基于经验学习的字典,其更新准则是对字典Φ的原子,即其列向量按顺序处理,在算法的训练过程中,其每步迭代中均有稀疏编码和字典更新2个步骤。
该算法的实质是求解下式的优化问题,即
minΦ,A‖X-ΦA‖2F s.t. i,‖αi‖0≤M。(10)
式中:X={xi}Ni=i∈Rm×N;A为αi组成的稀疏矩阵A={αi}Ni=i∈RK×N;Φ∈Rm×K表示过完備字典。
在稀疏编码阶段,假定字典Φ是固定的,式(10)的优化问题转化为搜索相应于字典矩阵Φ的系数矩阵A的稀疏表示问题,则式(10)改写为
minxi‖xi-Φai‖22 s.t. ‖αi‖0≤M,i=1,2,3,…,N。(11)
式(11)的求解与式(3)在本质上相同,可以通过不同的稀疏编码算法求解。
在字典更新阶段,假设字典Φ及A是固定的,每次仅更新字典Φ的第k列用k表示,以及相应的系数,它对应于A的第k行,记为αkT。则式(10)的目标函数可改写为
‖X-ΦA‖2F=‖X-∑Kj=1jαjT‖2F=‖(X-∑j≠kjαjT)-kαkT‖2F=‖Ek-kαkT‖2F。
(12)
式中矩阵Ek为舍去Φ的第k个原子k后,所有N个数据向量的误差。
通过更新字典原子k和稀疏编码向量αkT可得到更紧凑的字典集合,对矩阵ERk进行秩-1近似逼近的SVD算法,可有效地最小化式(12)的逼近误差。
若定义ωk为使用了字典原子k数据xi的索引集,即ωk={i|1≤i≤K,αkT(i)≠0},定义矩阵Ωk∈RN×|ωk|,其元素仅在(ωk(i),i)处的值为1,其他处为0,且记αkT、Ek去零收缩后的向量、矩阵分别为αkR=αkTΩk∈R|ωk|,ERk=EkΩk∈RN×|ωk|。
此种情形下,式(12)的目标函数等价于
‖EkΩk-kαkTΩk‖2F=‖ERk-kαkR‖2F。(13)
进一步应用SVD算法,即有ERk=UΔVT,其中:U、V为正交矩阵;Δ为对角矩阵。定义U的第1列为k的解,系数向量αkR为V的第1列和Δ[1,1]的乘积,在求解过程中还需注意保持字典Φ的归一化处理。不断重复稀疏编码和字典更新2个步骤,直到满足式(10)的停止条件为止。
综上,为求解式(10)的优化问题,获取表示数据集X的最好字典集合Φ,K-SVD算法具体实现步骤如下:
Step 1:初始化字典矩阵,置J=1,且Φ(0)∈Rm×K的列具有l2范数归一化;
Step 2:稀疏编码阶段:使用稀疏编码算法求解对应xi的稀疏向量αi,即
minαi‖xi-Φαi‖22 s.t. ‖αi‖0≤M,i=1,2,…,N;
Step 3:字典更新阶段:对字典Φ(J-1)中的每列(k=1,2,…,K)进行更新;
首先,定义使用原子的数据向量的索引集为
ωk={i|1≤i≤N,αkT(i)≠0};
其次,计算误差矩阵Ek,Ek=X-∑j≠kjαjT;
选择相应于ωk的列对Ek收缩,得到ERk;
最后,使用SVD分解ERk=UΔVT,选择更新后的字典列向量~k是U的第1列,更新系数向量αkR是V的第1列和Δ[1,1]的乘积;
Step 4:令J=J+1,返回Step2,直至满足式(10)的收敛或停止条件为止。
2.2 OMP算法
针对式(3)求解具有稀疏约束的稀疏编码问题时,作为一类贪婪算法求解策略,匹配追踪(matching pursuit,MP)算法或OMP算法是一类有效的求解手段。MP算法中,字典原子不是相互正交的向量,这使得算法每次迭代的结果是次最优的,OMP算法是MP算法的改进。
在统计建模中,贪婪步进最小二乘也被称为前项步进回归,在信号处理中的算法则称之为MP或OMP,其目的是在求解稀疏编码向量阶段,在每一步选择与当前残差具有最高相关性的原子。选择原子后,将信号正交投影到所选原子的空间,重新计算残差,并重复该过程。因此,在精度要求相同的情况下,OMP算法的收敛速度更快。
为求解稀疏编码向量的最优估计值,针对优化问题式(3),可重写为
α^=argminα‖Φα-x‖22 s.t. ‖α‖0≤M。(14)
为求解式(14),OMP算法的具体实现步骤如下:
Step 1:初始化残差向量r0=x,索引集Λ0=,迭代次数t=1;
Step 2:尋找索引χt。χt为残差r和字典矩阵的列向量i中具有最大内积时所对应的索引,即
χt=argmaxi=1,2,…,K|〈rt-1,i〉|=argmaxi=1,2,…,KrTt-1i,
该步骤是一个贪心选择求解过程;
Step 3:增广索引集,选择索引集Λt=Λt-1∪{χt},更新字典Φt=[Φt-1,χt],注意Φ0是空矩阵;
Step 4:为获取新的数据表示,需求解最小二乘问题,即
αt=argminαt‖x-Φtαt‖=(ΦTtΦt)-1ΦTtx;
Step 5:更新残差rt=x-Φtαt;
Step 6:t=t+1,若t≤M,则返回Step2。
3 基于稀疏表示的时间序列预测全局模型
本节考虑将稀疏表示方法与KELM结合构成全局预测模型的一种实现。首先,将历史电力负荷等数据构成的时间序列数据组成具有时延的输入—输出数据对。其次,将训练数据进行稀疏分解与变换,映射至稀疏域中,借助用于稀疏分解的字典所选择的基向量,所得到的稀疏编码向量就是训练输入数据的稀疏表示,即获取了输入数据的一种隐模式表达。最后,与相应目标输出配对,通过KELM全局回归模型进行训练。
针对单变量时间序列,建立待预测模型为
y^i+h=f(xi)=f(yi,yi-τ,…,yi-(m-1)τ)。(15)
式中:y^i+h为模型预测输出,i=1,…,N,h为步长;m为嵌入维数;τ为延迟常数;f(·)可采用KELM完成。
对于节点激活函数h(x),隐含层节点数为L,具有单输出的标准单层前馈神经网络(single-hidden layer feedforward neural network, SLFN),其网络节点的输出为
f(x)=∑Lj=1θjh(x;ωj,bj)=hT(x)θ。(16)
式中:ωj是连接输入层与第j个隐含层节点之间的权值向量;θj是连接输出层与第j个隐含层节点之间的权值θ=[θ1,…,θL]T;bj是第j个隐含层节点的阈值;h(x;ωj,bj)简记为hj(x),则h(x)=[h1(x),…,hL(x)]T是ELM中与输入有关的隐含层特征映射向量。
不同于常规的SLFN方法,ELM的隐含层节点激活函数在训练期间是确定的,其初始参数设置可以通过均匀分布的随机数产生,仅需调整输出层权值即可,这使得其训练学习过程可转换为求取最优权值向量θ的估计问题,而从理论上可以证实ELM具有万能逼近特性,是一种通用函数逼近器。
ELM的最优权值问题求解,由l2正则化优化问题进行求解,即
θ=HTHHT+INη-1Y。(17)
式中:矩阵H=[h(x1),…,h(xN)];η是正则化参数;目标矩阵Y=[y1,…,yN]T;单位阵IN维数为N×N。
隐含层特征映射h(x)未知时,定义核矩阵为
由式(16)和式(18)可得KELM的输出为
核函数k(xi,x)通常选取高斯核函数,即
式中ζ为函数的宽度参数,设定函数的径向作用范围。参数η和ζ可通过交叉验证法给定。
针对时间序列预测,基于K-SVD-OMP算法的全局预测方法的具体实现步骤如下:
Step 1:建立训练数据集{xi;yi}Ni=1,测试数据集{xti;yti}N1i=1,其中:xi,yi分别为训练数据集的输入与输出;xti,yti分别为测试数据集输入与输出;
Step 2:针对X={xi}Ni=i∈Rm×N,基于2.1节的K-SVD算法获取经过学习的紧凑字典Φ,其中算法中的稀疏编码采用OMP算法;
Step 3:在获取字典Φ的基础上,基于2.2节的OMP算法进行稀疏编码求解,计算每个xi所对应的稀疏编码向量αi;
Step 4:以αi作为输入,结合相应的目标输出yi,建立全局预测模型。预测模型f(·)可应用式(19)构建;
Step 5:针对测试数据xti,使用2.2节的OMP算法进行稀疏编码求解,获取相应的稀疏编码向量αti;
Step 6:将αti作为模型的测试输入,计算预测输出y^ti=f(αti)。
4 中、短期电力负荷峰值预测实验
本节将给出2个中、短期负荷预测实验的实例,以验证本文方法的有效性,由式(15)对包含电力负荷值及其他影响因素的实验数据进行时间序列建模。
考虑到不同字典、不同稀疏编码算法对于预测结果的影响,实验中的初始字典选择除了考虑时延输入数据向量外,也考虑了DCT字典,此外还考虑了非字典学习的稀疏编码算法,稀疏编码算法也考虑采用LASSO算法。因此,对比方法有其他稀疏表示建模算法,如DCT-LASSO、DCT-OMP、K-SVD-LASSO等。
实验结果的评价采用平均绝对值百分比误差(mean absolute percentage error, MAPE)、均方根误差(root mean square error, RMSE)和相对误差(relative error,RE),即
式中:yi是负荷实际数值;y^i是负荷预测值;n表示负荷的采样点数目。
另外,实验平台为win7 64位操作系统,且在基于Intel(R) Core i7、2.80 GHz双核CPU处理器,内存8 G的计算机上应用MATLAB R2012a软件进行不同预测方法的比较。
4.1 中期电力负荷预测实验
实验选取欧洲EUNITE 网络组织的中期负荷预测竞赛提供的电力负荷实际数据集[23]。为了避免气候因素的影响,采取数据分割的方式,选取冬季时段的历史负荷数据1997年1月~3月、1997年10月~1998年3月、1998年10月~12月为训练数据集,其任务是预测1999年1月,即未来31 d内每日最大电力负荷值。预测模型的输入为15维,其中日期信息为七位二进制编码、节假日信息为一位二进制编码、电力负荷值的实际时间序列数据的嵌入维为7,这与文献[6]一致。文献[6]用LIBSVM 软件完成并取得当年竞赛最好成绩。注意在模型训练完成后,对未来31 d进行预测时需采用迭代预测方式进行。
实验中:K-SVD算法选取K=15;迭代次数J=100;高斯核函数ζ=5;正则化系数η=102。图1给出了在稀疏度M不同取值下,不同稀疏表示方法的预测精度比较,可以看出,M为5时,其预测精度最好。
为进一步衡量本文方法的预测效果,取M=5的情形,对K-SVD-OMP方法与非字典学习的稀疏表示建模方法,以及采用单一KELM、SVM、ELM方法的预测结果进行比较,其中,非字典学习的稀疏表示方法中使用了DCT字典。对比方法中,设置LASSO算法的λ1=0.4,调用CVX软件进行求解,单一KELM及SVM均选取相同的高斯核函数, SVM的惩罚参数C=4 096,不敏感损失ε=0.1,ELM的隐含层激活函数为Sigmoid函数,隐含层节点数目L=50。
表1列出了单一预测方法与不同稀疏表示算法结合KELM、SVM、ELM方法的预测结果数值比较。可以看出,不同稀疏表示建模方法的預测精度均有提升,取得了很好的预测效果,其中,基于K-SVD-OMP算法的稀疏表示建模方法取得了最好的预测效果,且当全局模型选取为KELM时,其MAPE值最低。表1还给出了不同稀疏表示算法结合KELM、SVM、ELM在训练时的CPU运行时间比较,可以看出与单一预测方法相比,训练时间略有增加,其中,DCT-OMP算法的计算效率最高, K-SVD-OMP算法的计算效率优于K-SVD-LASSO算法。
图2给出了不同稀疏表示建模方法与单一SVM、KELM方法的绝对百分比误差(aboluate percentage errors, APE)的箱线图比较,可以看出,基于K-SVD的稀疏表示建模方法优于采用DCT字典的方法,且K-SVD-OMP结合KELM的方法能取得较好的预测结果。
图3进一步给出了K-SVD-OMP结合KELM方法与其他稀疏表示建模方法及单一SVM、KELM方法对未来31 d内的峰值预测结果比较。图4则给出了不同预测方法相应的误差比较。由图3、图4可见,基于K-SVD的稀疏表示建模方法的相对误差波动较小,呈现出较好的预测效果。
4.2 北美电力公司短期电力负荷预测实验
本节短期负荷预测实例实验选取北美电力公司提供的电力负荷数据集[24]进行,该数据集包括从1985年1月1日至1991年3月31日之间每天每小时的温度和电力负荷数值。每日预测在上午8点进行,预测次日一整天,从当日24点至次日24点,即未来16~40 h的电力负荷,周五预测整个周末和周一以及未来16~88 h的电力负荷。预测任务是1990年11月26日24点至12月3日24点之间的每小时电力负荷值。
实验的训练数据集选取待预测月份的前2个月和对应于同一时间段的上一年历史负荷和温度数据。模型输入为历史负荷数据xiL与历史温度数据xiT,即xi=(xiT,xiL),其中历史负荷数据xiL中嵌入维数m为4、延迟常数τ为5,历史温度数据xiT中嵌入維数m为9、延迟常数τ为3。这与文献[24]一致,采用式(15)的时间序列建模方式,取预测步长h=16,训练一旦完成后,基于模型对测试区段采用迭代方式进行预测。
本小节实验中:K-SVD算法选取K=40;迭代次数J=100;高斯核函数的参数ζ=5;正则化参数η=100。图5给出了在稀疏度M不同取值下,不同稀疏表示方法的预测精度比较,可以看出,M为5时,其预测精度最好。
同4.1节,为进一步衡量本文方法的预测效果,取M=5的情形,本文的K-SVD-OMP全局建模方法与采用DCT字典的稀疏表示建模方法,及采用单一SVM、ELM、KELM方法的预测结果进行了比较,其中,在LASSO算法中选择参数λ1=0.3,其他对比方法中,单一KELM及SVM方法也均选取相同高斯核函数,SVM的惩罚参数C=16,不敏感损失参数ε=0.1, ELM的参数设置同4.1节。
表2详细列出了单一预测方法与基于不同稀疏表示算法结合KELM、SVM、ELM的全局建模方法的预测结果数值比较。可以看出,不同稀疏表示建模方法的预测精度均有提升,取得了很好的预测效果,其中,基于K-SVD-OMP方法的稀疏表示建模方法取得了最好的预测效果,且当全局模型选取为KELM时,其MAPE值最低。
此外,本文方法与文献[24]所提方法的结果相比较,其预测精度也较优。表2还给出了不同稀疏表示算法结合KELM、SVM、ELM在训练时的CPU运行时间开销比较,与单一预测方法相比,其训练时间略有增加,其中,DCT-OMP算法结合ELM方法的计算效率最高,K-SVD-OMP算法结合ELM方法的计算效率次之,但与K-SVD-LASSO算法相比,K-SVD-OMP算法的计算效率又略优之。总体来看,在训练时间的耗时上,基于稀疏表示的特征提取算法作为预测模型的预处理手段还是可以满足实际需求的。
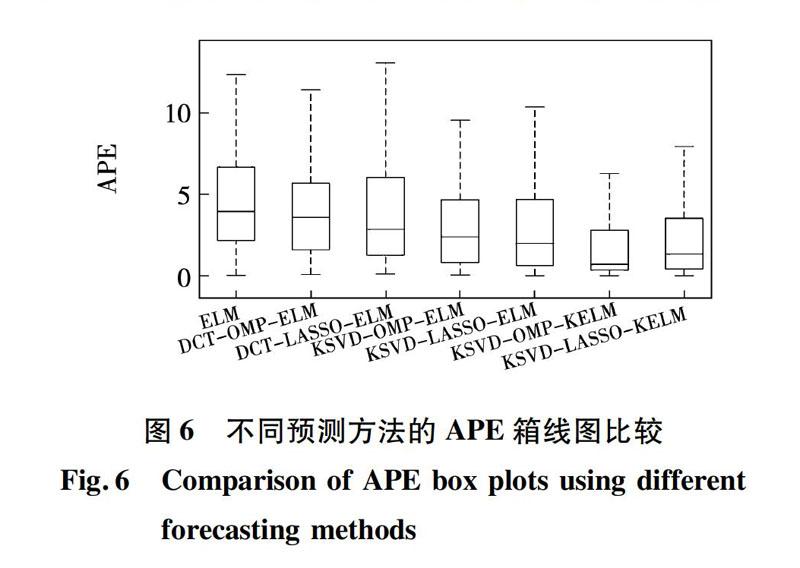
图6给出了不同稀疏表示方法与单一SVM、KELM方法的APE箱线图比较,可以看出,在APE指标下,基于K-SVD的稀疏表示建模方法优于采用DCT字典的稀疏表示建模方法,且K-SVD-OMP结合KELM的全局建模方法取得了较好的预测结果。
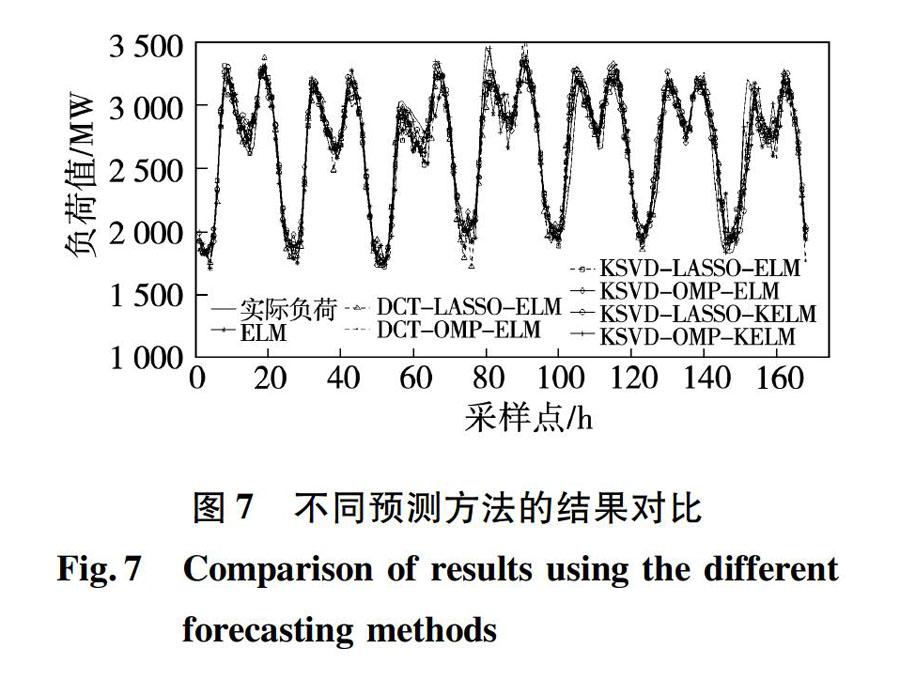
图7给出了不同稀疏表示方法与实际电力负荷值在测试集上的预测结果比较,相应地,图8给出了不同预测方法对测试集上一周范围时间内的每小时进行预测的相对误差。由图7、图8可见,基于K-SVD的稀疏表示预测方法的相对误差仍然波动较小,呈现出较好的预测效果。
5 结 论
针对中、短期电力负荷预测,提出一种基于K-SVD-OMP的稀疏表示全局建模方法。该方法在字典学习阶段,采用了K-SVD算法,对初始字典逐列进行更新,较直接采用DCT字典的非字典学习算法相比,在满足稀疏度的条件下能获得更紧凑的字典集合,进一步减少了重构误差且具有一定的自适应性。在稀疏编码求解阶段采用OMP算法,较之LASSO算法避免了求解过程中计算复杂且因惩罚项是l1范数,会导致所得解向量中非零值过多的缺点。另一方面,由于基于稀疏表示建模方法的全局回归模型选择KELM,这使得建模效果更为突出。
将所提出的基于K-SVD-OMP算法的稀疏建模方法应用于不同地区的电力负荷峰值预测实例中,实验结果证实,与已有的单一SVM或ELM预测方法相比而言,稀疏表示与KELM结合的预测方法虽然在模型训练时增加了一定的运行时间开销,但体现出较好的潜在特征表示能力,进一步提升了模型预测精度,体现出较好的预测效果。未来的研究还可考虑其他基于稀疏表示的改进字典学习算法,将其应用于电力负荷预测中。
参 考 文 献:
[1] KHUNTIA S R, RUEDA J L, van der MEIJDEN M A M M. Forecasting the load of electrical power systems in mid-and long-term horizons:
a review[J].IET Generation, Transmission & Distribution, 2016, 10(16):
3971.
[2] KUSTER C, REZGUI Y, MOURSHED M. Electrical load forecasting models:
a critical systematic review[J]. Sustainable Cities and Society, 2017, 35:257.
[3] CHUJAI P, KERDPRASOP N, KERDPRASOP K.Time series analysis of household electric consumption with ARIMA and ARMA models[C]//Proceedingsof the International Multi-Conference of Engineers and Computer Scientists, March 13-15,2013, Hong Kong, China.2013:
295-300.
[4] 李军,李青.基于CEEMDAN-排列熵和泄漏积分ESN的中期电力负荷预测研究[J].电机与控制学报,2015, 19(8):70.
LI Jun, LI Qing. Medium term electricity load forecasting based on CEEMDAN-permutation entropy and ESN with leaky integrator neurons[J]. Electric Machines and Control, 2015,19(8):70.
[5] 鄭高,肖建.基于区间二型模糊逻辑的电力负荷预测研究[J].电机与控制学报, 2012,16(9):26.
ZHENG Gao, XIAO Jian. Forecasting study of power load based on interval type-2 fuzzy logic method[J]. Electric Machines and Control,2012, 16(9):26.
[6] CHEN B J, CHANG M W, LIN C J. Load forecasting using support vector machines:
a study on EUNITE competition 2001[J]. IEEE Transactions on Power Systems, 2004,19(4):1821.
[7] 段青, 赵建国, 马艳.优化组合核函数相关向量机电力负荷预测模型[J].电机与控制学报,2010,14(6):33.
DUAN Qing, ZHAO Jianguo, MA Yan. Relevance vector machine based on particle swarm optimization of compounding kernels in electricity load forecasting[J]. Electric Machines and Control, 2010,14(6):33.
[8] HUABG G B, ZHU Q Y,SIEW C K. Extreme learning machine:
theory and applications[J]. Neurocomputing, 2006, 70(1):489.
[9] 李军,李大超. 基于优化核极限学习机的风电功率时间序列预测[J].物理学报, 2016, 65(13):130501.
LI Jun, LI Dachao. Wind power time series prediction using optimized kernel extreme learning machine method[J]. Acta Physica Sinica,2016, 65(13):130501.
[10] CHEN Y, KLOFT M, YANG Y, et al.Mixed kernel based extreme learning machine for electric load forecasting[J]. Neurocomputing, 2018, 312:90.
[11] 刘念, 张清鑫, 刘海涛. 基于核函数极限学习机的微电网短期负荷预测方法[J]. 电工技术学报, 2015, 30(8):218.
LIU Nian, ZHANG Qingxin, LIU Haitao. Online short-term load forecasting based on ELM with kernel algorithm in micro-grid environment[J].Transactions of China Electrotechnical Society,2015,30(8):
218.
[12] ELAD M, FIGUERIREDO M A T, MA Y. On the role of sparse and redundant representations in imageprocessing[J]. Proceedings of the IEEE,2010, 98(6):972.
[13] AHARON M,ELAD M,BRUCKSTEIN A.K-SVD:an algorithm for designingovercomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311.
[14] FORERO P A, RAJAWAT K, GIANNAKIS G B. Prediction of partially observed dynamical processes over networks via dictionarylearning[J]. IEEE Transactions on Signal Processing, 2014, 62(13):
3305.
[15] ROSAS-ROMERO R,DIAZ-TORRES A, ETCHEVERRY G. Forecasting of stock return prices with sparse representation of financial time series over redundant dictionaries[J]. Expert Systems with Applications,2016,57:37.
[16] BIANCHI F M, DE SANTIS E, RIZZA A, et al.Short-term electric load forecasting using echo state networks and PCA decomposition[J]. IEEE Access, 2015, 3:1931.
[17] 田中大, 李树江, 王艳红,等. 基于KPCA优化ESN的网络流量预测方法[J].电机与控制学报, 2015,19(12):114.
TIAN Zhongda, LI Shujiang, WANG Yanhong, et al.Network traffic prediction method based on KP CA optimized ESN[J]. Electric Machines and Control, 2015, 19(12):114.
[18] TROPP J A, GILBERT A C. Signal recovery from random measurements via orthogonal matching pursuit[J]. IEEE Transactions on Information Theory, 2007,53(12):4655.
[19] RUBINSTEIN R,ZIBULEVSKY M,ELAD M.Efficient implementation of the K-SVD algorithm using batch orthogonal matching pursuit[R].Computer Science Department, Israel:Technion,2008.
[20] FIGUEIREDO M A T. Adaptive sparseness for super vised learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003,25(9):1150.
[21] TIBSHIRANI R.Regression shrinkage and selection via the LASSO[J].Journal of the Royal Statistical Society:Series B(Methodological), 1996,58(1):267.
[22] GRANT M, BOYD S, YE Y.CVX:Matlab Software for Disciplined Convex Programming[EB/OL]. (2013-09-01) [2018-04-01]. http://cvxr.com/cvx.
[23] OTTO P. World-wide Competition within the EUNITENetwork[EB/OL]. (2001-05-01) [2018-04-06].http://neuron.tuke.sk/competition/index.php.
[24] ELATTAR E E, GOULERMAS J Y, WU Q H. Electric load forecasting based on locally weighted support vector regression[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C, 2010, 40(4):438.
(編辑:邱赫男)
收稿日期:
2018-12-17
基金项目:国家自然科学基金(51467008)
作者简介:李 军(1969—),男,博士,教授,研究方向为计算智能、非线性系统预测、建模与预测;
李世昌(1993—),男,硕士研究生,研究方向为电力负荷预测。
通信作者:李 军
猜你喜欢 负荷预测特征提取 浅析配电网负荷预测的应用需求及方法科技资讯(2019年10期)2019-07-08关于提升配网电压合格率的策略研究山东工业技术(2018年21期)2018-12-07基于人工神经网络的短期居民用电负荷预测研究科技创新与应用(2017年23期)2017-09-01基于曲率局部二值模式的深度图像手势特征提取计算机应用(2016年10期)2017-05-12基于ELM和证据理论的纹理图像分类计算技术与自动化(2017年1期)2017-05-08基于主成分分析的BP神经网络预测电力负荷数学学习与研究(2016年23期)2017-03-15组合预测法在中长期电力负荷预测中的研究与应用科技与企业(2016年4期)2016-10-21镜像式单摄像机立体视觉传感器对弹簧几何尺寸的测量现代电子技术(2015年18期)2015-09-16一种基于Kinect的手势识别系统物联网技术(2015年5期)2015-07-18基于内容的图像检索现代电子技术(2014年7期)2014-04-18



