刘田田


摘 要:現有的信用评估模型往往需要在建模前预设模型的基本形态结构,极易因函数形式的误设导致评估结果误差较大,同时现有模型大多面向传统大中型企业、消费信贷用户,对农户这一借款主体缺乏适用性。基于宿迁地区某农村信用社的农户信贷数据库,设计一种面向我国农户贷款信用风险评估模型——Relief-GEP模型。模型首先使用Relief算法,对建模样本集维度进行删减,剔除对预测违约概率影响不大的各项指标,在摈弃部分噪声数据的同时提高后续建模精度;在缺乏最优函数形式的先验信息情况下使用基因表达式编程算法,以“适者生存”的逻辑通过反复演化迭代,动态构筑模型的核心部分。实证研究表明,Relief-GEP模型相比于当前流行的12个信用风险评估模型,拥有更优的拟合精度与更好的泛化能力。
关键词:仿真建模;信用风险;特征权重选择算法;基因表达式编程算法
DOI:10. 11907/rjdk. 202034 开放科学(资源服务)标识码(OSID):
中图分类号:TP303 文献标识码:A 文章编号:1672-7800(2020)011-0079-05
A Relief-GEP Model for Credit Risk Evaluation of Loans for Farmers
LIU Tian-tian
(College of Information and Electromechanical Engineering, Jiangsu Open University, Nanjing 210017,China)
Abstract:The existing credit evaluation model needs to presuppose the basic structure of the model itself before the modeling process, then the error of the evaluation result is very easy to be caused by the setting error of the function form of the model. At the same time, most of the existing models are designed for traditional large and medium-sized enterprises or consumer users, and are lack of applicability to farmers who wish to apply for loans. Based on the credit database of a rural credit cooperative in Suqian area, this paper designs a credit risk evaluation model - the Relief-GEP model which is oriented to evaluate the credit risk of loans for farmers in China. The model firstly uses the relief algorithm to reduce the dimension of the sample set for modeling, eliminate all the indexes that have little effect on the prediction of default probability and some noise data to improve the accuracy of subsequent modeling process, and then in the condition of lack of the prior information of the optimal function form, the gene expression programming algorithm is employed with the logic of “survival of the fittest” and dynamically construct the model through the repeated evolutionary iteration. The empirical study shows that the Relief-GEP model has better fitting precision and better generalization ability than the 12 credit risk evaluation models that are popular in the current academic and industry circles.
Key Words:simulation modeling; credit risk; relief algorithm; gene expression programming algorithm
0 引言
根据2016年国务院印发的《推进普惠金融发展规划(2016-2020)》,农民群体是中国普惠金融[1]的重点服务对象之一。但迄今为止,全国农户的贷款可得性、贷款覆盖率等统计指标依然相对较低[2],究其根本原因,主要在于农户贷款的信用风险较高。信用风险[3]指获得信用支持的债务人不能遵照合约按时足额偿还本金和利息的可能性。农户贷款的特点是贷前调查不易、贷款金额小、居住分散、清收成本高,这使得传统的基于信贷员逐笔审核的信用风险评估机制难以作为。为降低信用风险管理成本,提高贷款决策效率,目前信贷机构一般选择信用评估模型[4]对贷款农户信用风险进行批量化、自动化预测与管理,而当前商业银行或农村信用社大多已有面向大中型企业、上市公司、个人消费贷的信用评估模型,但却缺乏专门针对农户的风险评估方法与模型。
王树娟等[5]在国内最早研究农户信用风险评估模型,将农户信用分为户主素质、资金信用和经营能力等3个方面7个指标,运用模糊数学方法建立综合评价数学模型,采用定量分析方法评估农户信用;王慧等[6]采用生态学中修正BS模型,利用末位淘汰机制对农户信用作用建模,分析末位淘汰机制对于农户信用水平的影响;王思宇等[7]将LightGBM算法应用于研究用户信用风险中,发现其具有更快的训练速度和更高的训练效率。
国外对农户信用风险评估模型也有研究[8-9],但由于各国农业文化的差异,这些研究对我国农户信用风险评估指导有限[10-11]。
我国农户信用风险评估模型研究成果数量不多,采用的模型技术大多较为老旧,如基于传统统计学方法的logistic回归、probit回归等模型[12]。基于此,本文将应用新颖的人工智能、机器学习模型,采用特征权重选择算法对样本集进行处理,运用基因表达式编程算法构筑信用评估模型,实验表明该模型在训练效率、泛化能力上均表现优异。
1 Relief-GEP算法设计
针对农户信用风险评估的实际需求与现有模型存在的问题,本文设计一种面向我国农户贷款信用风险的评估模型——Relief-GEP模型。Relief-GEP模型首先使用Relief算法,对建模样本集进行维度删减,只保留预测农户违约概率意义较大的指标,从而解决构建模型时的指标选取问题,尽可能摈弃噪声信息,提高建模效率。之后基于基因表达式编程(Gene Expression Programming,GEP)模型动态构筑核心的信用评估模型,从而避免在缺乏先验信息的情况下误设函数形式问题。
1.1 Relief算法
Relief特征权重选择算法[13]主要原理:从样本集D中随机选择一个样本xi(i∈{1,2,?,n}),之后在D中寻找k个与xi距离最近且类标签相同的样本,其集合记为Shit,并在D中寻找k个与xi距离最近且类标签不同的样本,其集合记为Smiss。分别计算各属性与Shit中样本在同一属性上的平均距离、各属性与Smiss中样本在同一属性上的平均距离。
若前者大于后者,则表明该属性在异类标签样本上能够较好区分,增加该属性权重;反之则认为该属性不能有效区分异类样本,减少该属性权重,重复多次得到较为稳定的各属性权重。Relief特征权重选择算法对各属性重要程度的评价是正向的,即评价结果值越大,对应的属性对预测因变量的重要性越强。
1.2 GEP算法
基因表达式编程算法(GEP)是一种较为新颖的进化智能算法[14],其将多个变量间的表达式首先表示为树结构,之后通过广度优先遍历该树结构表达式,得到以线性串结构表示的“基因染色体组”。线性串结构与树结构的表达式可以互相转化,且转化结果唯一。
GEP 的基因用线性编码符号串表示,由头部和尾部共同决定。头部可以包含函数运算符或运算变量,尾部仅包含运算变量。若头部长度为h,尾部长度为t,则线性串结构编码需满足以下函数关系:
t=h?(n-1)+1 (1)
其中,n為运算符可支持的最大可带运算变量个数,例如乘号运算符最大可以携带两个运算变量。
1.3 Relief-GEP信用评估模型设计
Relief-GEP农户信用评估模型步骤如下:
首先对用于建模的农户历史信贷数据集进行数据清洗。数据清洗工作主要包括剔除含有缺失值的样本,对来自不同数据源的样本进行单位统一化(如借款金额的单位元与万元之间的不一致性),剔除明显含有错误取值指标的样本等。
在完成原始样本集数据清洗工作后,使用Relief算法对建模样本集中各变量指标与因变量(是否违约)的影响重要性进行判断。基于各指标在Relief算法中的重要性得分,剔除分值为负的各项指标,从而在压缩建模样本集维度,提高后续建模效率之余,将预测违约概率关联性不大的各项指标在建模步骤前剔除,避免冗余属性所含的噪声信息对最终拟合得到的违约概率产生影响。
基于维度精简的建模样本使用GEP算法构建模型。选择常规的加减乘除、乘方、自然对数、正余弦、大于、小于、等于、大于等于、小于等于等运算符作为备选运算符,供GEP算法在迭代中使用。算法的停止条件为迭代次数达到预设的最大迭代次数阈值。
在完成GEP算法迭代后,根据算法的拟合结果将农户违约概率的可预测模式总结为计算机逻辑语言,之后进一步将其转化为便于理解的自然语言。
在使用Relief-GEP农户信用评估模型对新的样本进行违约概率预测时,首先根据建模阶段Relief算法发现的弱关联指标对新样本维度进行削减,随后将降维了的新样本带入训练好的GEP算法预测模式中,得到最终的预测违约概率。
2 实证研究
2.1 实证数据
本文的研究数据来自宿迁地区某农村信用社农户信贷数据库。数据库搜集了该地区2017年共645份面向农户发放贷款的历史记录,除具有较大的样本规模外,数据集也具有较好的时效性。
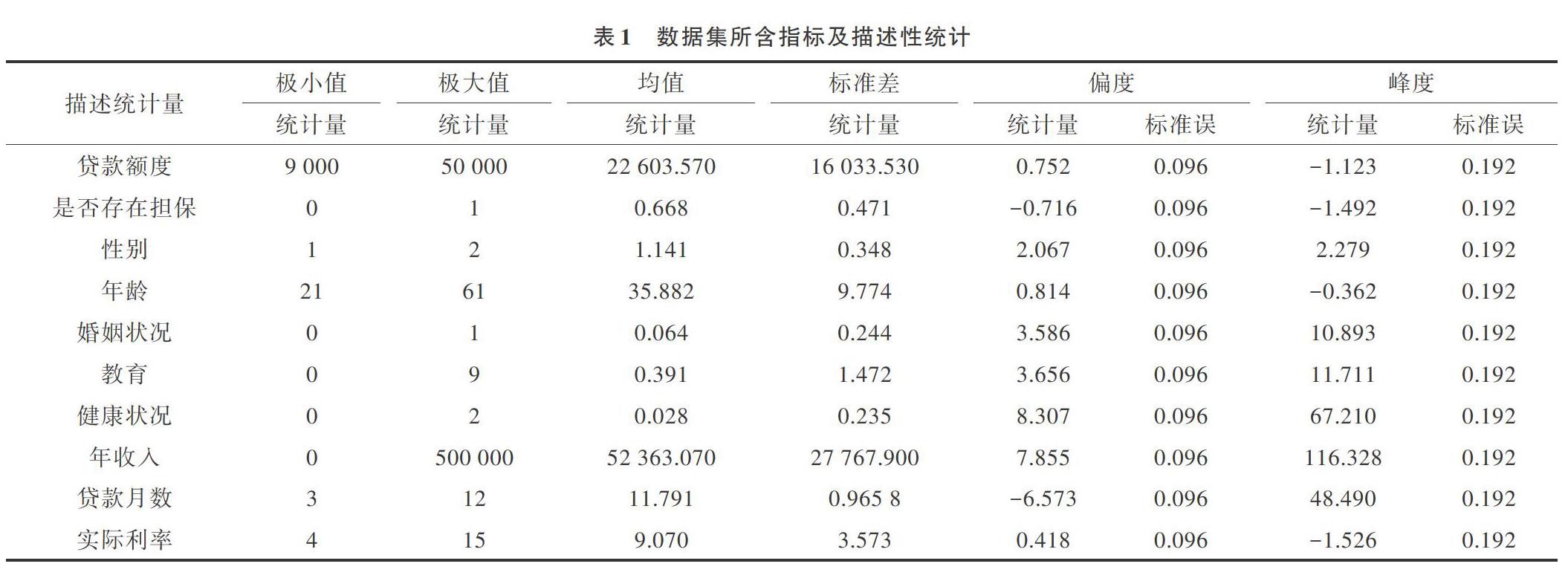
数据集中共含有11维变量指标,分别为该笔贷款的额度、该筆贷款是否存在担保、贷款者性别、贷款者年龄、贷款者婚姻状况、贷款者受教育水平、贷款者健康状况、贷款者年收入、该笔贷款的持续月数、该笔贷款的实际利率与该笔贷款最终是否违约。
其中,贷款额度、年龄、年收入、贷款月数、实际利率均为连续性变量,剩余变量均为二值或多值离散型变量。是否存在担保为二值哑变量,取值为1表明存在担保,为0表明不存在;性别为二值哑变量,男性为2,女性为1;婚姻状况为二值哑变量,未婚为0,已婚为1;教育为多值离散型变量,取值为0~9之间的整数,取值越大表明受教育程度越高;健康状况为二值变量,取值为0表明健康,为2表明存在一些健康问题。
表1给出本文实证数据集中自变量各指标的描述性统计情况,相关计算由SPSS 20.0软件完成。
从表1可以看出,当地贷款农户的借款金额一般不超过5万元,一定程度上均属于小额贷款,同时大多数贷款农户都存在贷款担保人。而在贷款农户中,女性数量明显高于男性,未婚者居多,在年龄上又以中年人居多。在受教育情况方面,大多数农户受教育程度不高。
2.2 实证设计
选择当前最为成熟与流行的12种信用评估方法:决策树(DT)、判别分析(DA)、logistic回归、线性核函数的支持向量机(SVM-liner)、高斯核函数的支持向量机(SVM-rbf)、多项式核函数的支持向量机(SVM-polynomial)、k最近邻(k-NN)、朴素贝叶斯(NB)、k均值聚类(k-means)、径向基神经网络(RBF-ANN)、反向传播神经网络(BP-ANN)、自组织映射神经网络(SOM-ANN)。这12个模型应用广泛,有较好的代表性。
选用5折交叉法进行样本训练,划分测试样本。基于划分的训练样本模型对独立于训练样本的测试样本进行模型泛化能力检验。
采用AUC指标综合评判模型的平均预测能力和偏倚程度。AUC指标计算方法为:首先根据表2的混淆矩阵定义两个指标:
假正类率:
FPR=FPFP+TN (2)
真正类率:
TPR=TPTP+FN (3)
对输出结果为各样本预测违约概率的模型,根据模型预测结果中每个样本属于正类样本的概率从大到小排序,构成各样本的违约概率序列P,之后从高到低按序依次以序列P中的当前违约概率作为阈值,判断当所有被预测的样本以该阈值作为分类依据时的总体样本划分情况,即当各样本的预测违约概率大于该阈值时,将其划入违约类;反之,将其划入未违约类。之后计算两类样本的假正类率和真正类率值,形成一系列假正类率序列和真正类率序列。最后在二维坐标轴中以假正类率序列为横轴,真正类率序列为纵轴,绘制出对应的曲线,该曲线即为ROC曲线(Receiver Operating Characteristic),而ROC曲线下方与坐标轴围成的面积定义为AUC(Area Under Curve)值。
在Relief-GEP农户信用评估模型参数设置方面,选择剔除Relief算法识别结果中重要性系数小于0的指标,同时设置GEP算法的演化迭代停止阈值为300次,适应度函数设置为建模阶段的AUC指标值最大化。
最后,12个对比模型使用MATLAB编程实现,Relief算法基于RapidMiner软件运算,GEP算法基于GeneXproTools 5.0软件运行。
2.3 实证结果分析
表3展示Relief-GEP农户信用评估模型各指标对预测违约概率重要性的评价结果。
从表3中可以明显看出,在所用数据集各项指标中,性别因素对预测违约概率作用最为明显,作用力度在所有指标中占比超过了50%,其次分别为婚姻状况、教育、年龄、贷款实际利率等因素,而健康状况、贷款是否存在担保、贷款额度3项指标的Relief算法重要性得分均为负值,表明这3项指标对预测违约概率作用不强。故根据Relief-GEP农户信用评估模型设计原理,剔除这3项指标,从而实现训练样本降维,摈弃噪声信息。
图1进一步展示了Relief算法筛选对预测违约概率作用较大的各项指标后,GEP算法在训练阶段多次演化迭代过程中算法的适应度值变化情况。
从图1可以明显看出,在总计300次的迭代过程中,GEP算法的最优精度很快接近100%,同时GEP算法在迭代过程中的平均适应度、最优适应度两项指标总体上均随着迭代次数的增加而提高,表明GEP算法向最优解逼近的能力与效率均较强。与此同时,在整个迭代过程中,GEP算法的适应度也出现了多处“骤降”现象,表明GEP算法在迭代过程中能够有效跳出局部解空间,尝试在更广阔的解空间中寻找适应度更高的个体。
表4展示了在构建模型训练阶段与应用模型测试阶段参与比较的12个对比模型,与本文设计的Relief-GEP农户信用评估模型在训练阶段AUC指标值与测试阶段AUC指标值的具体取值情况。
由表4可以明显看出,在训练阶段,除k-means模型与SOM-ANN模型之外,其余模型的拟合AUC指标均在0.9以上,logistic、SVM-liner、SVM-rbf、SVM-polynomial、k-NN、BP-ANN与Relief-GEP模型的拟合精度更是达到了AUC值大于0.95的水平,这表明大多数模型在训练阶段都能较好地对训练样本中所含的拟合模式进行充分整合。而在所有表现较好的模型中,Relief-GEP模型的拟合精度最高,AUC值达到0.976 7,SVM-rbf与k-NN模型次之,AUC指标值分别为0.967 4与0.954 9,这表明相比于现有的12个代表性信用评估模型,Relief-GEP模型能够更好地挖掘训练样本中所蕴含的拟合模式。
从表4最右列可以发现,在训练阶段及测试阶段表现较好的模型,其预测AUC指标值相对于训练阶段均有不同程度降低,这表明训练样本集样本所含的信息中依然存在一定的噪声信息,从而干扰了模型对样本集中蕴含的违约概率精准识别。而在各模型中Relief-GEP模型拥有最高的预测精度,其测试阶段的AUC指标值达到0.956 2,在所有的13個模型中排名第一,其次为RBF-ANN模型与DA模型,AUC指标值分别为0.939与0.94。而剩余在训练阶段表现较好的各模型,在测试阶段性能均出现较大幅度的下降,AUC指标均未达到0.9,表明这些模型在训练阶段所表现出的较优性能很大程度上是由过度拟合问题造成的,因而其泛化能力较差。
在实际使用信用评估模型对各贷款农户进行贷前信用评估时,使用者往往仅能根据各备选模型对已有样本的拟合精度(相当于测试阶段模型的拟合结果)进行选择,故模型的稳定性与泛化能力尤为重要。本文设计的Relief-GEP农户信用评估模型,在训练阶段与测试阶段均表现出稳定的性能,较优的泛化能力,对新样本的违约概率预测能力较高,实用性强。
将Relief-GEP农户信用评估模型得到的最终违约概率预测模式以C++语言表述如下:
from math import *
def gepModel(d):
ROUNDING_THRESHOLD = 2.72727627255423
G2C4 = -8.23297830133976
y = 0.0
y = pow(d[0],3.0)
y = y + gepLT2C(gepGOE2G(((G2C4-d[5])+d[3]),exp(G2C4)),gepLogi((d[6]*d[3])))
y = y + gepLogi(pow(d[0],4.0))
if (y >= ROUNDING_THRESHOLD):
return 1
else:
return 0
def gepLT2C(x, y):
if (x < y):
return (x+y)
else:
return (x-y)
def gepGOE2G(x, y):
if (x >= y):
return (x+y)
else:
return atan(x*y)
def gepLogi(x):
if (abs(x) > 709.0):
return 1.0 / (1.0 + exp(abs(x) / x * 709.0))
else:
return 1.0 / (1.0 + exp(-x))
3 结语
本文设计了面向我国农户贷款信用风险评估的Relief-GEP模型。模型首先使用Relief算法删减对预测违约概率作用不大的冗余属性,摈弃一定的噪声数据,明晰了模型预测使用的指标,因而提高了后续建模的整体效率。在缺乏最优模型具体结构形态先验知识的情况下,结合“适者生存”的哲学思想,使用基因表达式编程算法对模型的最优结构不加限制地进行演化迭代寻优,最终构建出完整的农户贷款信用风险评估模型。基于宿迁地区某农村信用社农户信贷历史样本进行实证研究,结果表明,设计的Relief-GEP模型相比于当前流行的12种信用风险评估模型,拥有更好的建模样本拟合能力及更优的样本泛化能力。该模型形态结构十分灵活,但如果在建模前缺乏先验信息而以传统方式预设模型结构形式的情况下,则极易因函数形式误设导致模型识别精度不高,这需要在后续工作中进行改进。
参考文献:
[1] 王颖, 曾康霖. 论普惠:普惠金融的经济伦理本质与史学简析[J]. 金融研究, 2016,15(2):37-54.
[2] 张梓榆,温涛,王小华.“新常态”下中国农贷市场供求关系的重新解读——基于农户分化视角[J].农业技术经济,2018,17(4):54-64.
[3] MA X M, LV X L. Financial credit risk prediction in internet finance driven by machine learning[J]. Neural Computing and Applications,2019,31(12):128-135.
[4] ELIANA COSTA E SILVA,ISABEL CRISTINA LOPES,ALDINA CORREIA,et al. A logistic regression model for consumer default risk[J]. Journal of Applied Statistics,2020,47(13-15):1154-1168,159-1681.
[5] 王树娟, 霍学喜, 何学松. 农村信用社农户信用综合评价模型[J]. 财贸研究, 2005,16(5):35-39
[6] 王惠,王静.末位淘汰机制下的农户信用水平演化动态模拟仿真及案例检验[J].农林经济管理学报,2019,18(6):717-724.
[7] 王思宇,陈建平.基于LightGBM算法的信用风险评估模型研究[J].软件导刊,2019,18(10):19-22.
[8] MARTINE V,HAFSAH J,KERRI B. Risk preferences and poverty traps in the uptake of credit and insurance amongst small-scale farmers in South Africa[J]. Journal of Economic Behavior and Organization,2019,33(265):1482-1511.
[9] VIHI S K, JESSE B, DALLA A A ,et al. Analysis of farm risk and coping strategies among maize farmers in lere local government area of kaduna state, nigeria[J]. Asian Journal of Research in Agriculture and Forestry,2018,561(9):624-637.
[10] JAIN R, GOUR B, DUBEY S. A hybrid approach for credit card fraud detection using rough set and decision tree technique[J]. International Journal of Computer Applications, 2016,139(10):1-6.
[11] YU L, YANG Z, TANG L. A novel multistage deep belief network based extreme learning machine ensemble learning paradigm for credit risk assessment[J]. Flexible Services & Manufacturing Journal, 2016, 28(4):576-592.
[12] YASIN A,KADRIYE K. A jackknifed ridge estimator in probit regression model[J]. Statistics,2020,54(4):295-312.
[13] 肖利军,郭继昌,顾翔元.一种采用冗余性动态权重的特征选择算法[J].西安电子科技大学学报,2019,46(5):155-161.
[14] MOHSEN A,RAHIM T. A gene expression programming model for economy growth using knowledge-based economy indicators[J]. Journal of Modelling in Management,2019,14(1):921-937.
(責任编辑:杜能钢)
猜你喜欢 信用风险 我国国有商业银行信用风险管理研究科学与财富(2019年9期)2019-06-11基于模糊层次分析法的农户信用风险评级研究智富时代(2018年2期)2018-05-02基于模糊层次分析法的农户信用风险评级研究智富时代(2018年2期)2018-05-02我国中小企业私募债券信用风险研究中国管理信息化(2016年23期)2017-02-04当代外资银行风险管理研究现代经济信息(2016年13期)2016-06-17我国外资融资租赁公司面临的主要问题及解决方式商(2016年16期)2016-06-12