XX云计算平台
技术方案
第一版
目录
第1章 总述 5
第2章XX数据中心网络建设需求 6
2.1 传统架构存在的问题 6
2.2XX数据中心目标架构 7
2.3XX数据中心设计目标 8
2.4XX数据中心技术需求 9
2.4.1 整合能力 9
2.4.2 虚拟化能力 9
2.4.3 自动化能力 10
2.4.4 绿色数据中心要求 10
第3章XX数据中心技术实现 11
3.1 整合能力 11
3.1.1 一体化交换技术 11
3.1.2 无丢弃以太网技术 12
3.1.3 性能支撑能力 13
3.1.4 智能服务的整合能力 13
3.2 虚拟化能力 14
3.2.1 虚拟交换技术 14
3.2.2 网络服务虚拟化 16
3.2.3 服务器虚拟化 16
3.3 自动化 17
3.4 绿色数据中心 18
第4章XX云计算平台网络设计 19
4.1 总体网络结构 19
4.1.1 层次化结构的优势 19
4.1.2 标准的网络分层结构 19
4.1.3XX云计算平台数据中心网络结构 20
4.2 数据中心核心层设计 21
4.3 数据中心分布层设计 22
4.3.1 数据中心分布层虚拟交换机 22
4.3.2 数据中心分布层智能服务机箱 22
4.4 数据中心接入层设计 24
第5章 应用服务控制与负载均衡设计 28
5.1 功能介绍 28
5.1.1 基本功能 28
5.1.2 应用特点 29
5.2 应用优化和负载均衡设计 33
5.2.1 智能服务机箱设计 33
5.2.2 应用负载均衡的设计 36
5.2.3 安全功能的设计 39
5.2.4 SSL分流设计 41
5.2.5 扩展性设计 42
5.2.6 高可用性设计 43
第6章 网络安全设计 46
6.1 网络安全部署思路 46
6.1.1 网络安全整体架构 46
6.1.2 网络平台建设所必须考虑的安全问题 47
6.2 网络设备级安全 48
6.2.1 防蠕虫病毒的等Dos攻击 48
6.2.2 防VLAN的脆弱性配置 49
6.2.3 防止DHCP相关攻击 50
6.3 网络级安全 50
6.3.1 安全域的划分 51
6.3.2 防火墙部署设计 51
6.3.3 防火墙策略设计 53
6.3.4 防火墙性能和扩展性设计 53
6.4 网络的智能主动防御 54
6.4.1 网络准入控制 55
6.4.2 桌面安全管理 56
6.4.3 智能的监控、分析和威胁响应系统 58
6.4.4 分布式威胁抑制系统 61
第7章 服务质量保证设计 64
7.1 服务质量保证设计分类 64
7.2 数据中心服务质量设计 64
7.2.1 带宽及设备吞吐量设计 64
7.2.2 低延迟设计 66
7.2.3 无丢弃设计 67
第8章 网络管理和业务调度自动化 69
8.1 MARS安全管理自动化 69
8.2 VFrame业务部署自动化 69
第9章 服务器(UCS)组件及高可用性 70
9.1 思科统一计算系统(UCS)简介 70
9.2 云计算的基础----思科UCS Manager简介 72
9.3 云计算的扩展----数据中心的横向扩展 75
9.4 云计算的安全----纯硬件级的容错 76
第10章 两种数据中心技术方案的综合对比 79
10.1 技术方案对比 79
10.1.1 传统技术领域对比 79
10.1.2 下一代数据中心技术能力比较 80
10.2 技术服务对比 82
10.3 商务对比 83
10.4 总结 83
第11章 附录:新一代数据中心产品介绍 84
11.1 Cisco Nexus 7000 系列10插槽交换机介绍 84
11.2 Cisco Nexus 5000 / 2000系列交换机介绍 85
11.3 Cisco NX-OS 数据中心级操作系统简介 87
第1章
总述
为了进一步提升客户满意度,为用户提供更多增值服务,增强用户的产品忠诚度,需要为XX包括电视机的客户在内提供多样增值应用服务,首期考虑提供视频点播服务,未来可提供电子商务等多样化应用。考虑到潜在客户数较大,需要有一个健壮、有弹性和符合未来趋势变化的新一代系统架构。
XX电视机销售量20年保持国内市场第一,尤其是网络电视稳居第一,潜在用户数在数十万以上,为此,需要在绵阳建设一个可以充分面对未来应用和用户发展的新一代数据中心,同时在用户集中的城市的运营商托管服务器,充分利用流量分发和站点自动选择等技术,确保应用的最优化。这也是一些大型网站采用的方案。
第2章 XX数据中心网络建设需求
2.1 传统架构存在的问题
XX现有数据中心网络采用传统以太网技术构建,随着各类业务应用对IT需求的深入发展,业务部门对资源的需求正以几何级数增长,传统的IT基础架构方式给管理员和未来业务的扩展带来巨大挑战。具体而言存在如下问题:
l 维护管理难:在传统构架的网络中进行业务扩容、迁移或增加新的服务功能越来越困难,每一次变更都将牵涉相互关联的、不同时期按不同初衷建设的多种物理设施,涉及多个不同领域、不同服务方向,工作繁琐、维护困难,而且容易出现漏洞和差错。比如数据中心新增加一个业务类型,需要调整新的应用访问控制需求,此时管理员不仅要了解新业务的逻辑访问策略,还要精通物理的防火墙实体的部署、连接、安装,要考虑是增加新的防火墙端口、还是需要添置新的防火墙设备,要考虑如何以及何处接入,有没有相应的接口,如何跳线,以及随之而来的VLAN、路由等等,如果网络中还有诸如地址转换、7层交换等等服务与之相关联,那将是非常繁杂的任务。当这样的IT资源需求在短期内累积,将极易在使得系统维护的质量和稳定性下降,同时反过来减慢新业务的部署,进而阻碍公司业务的推进和发展。
l 资源利用率低:传统架构方式对底层资源的投入与在上层业务所收到的效果很难得到同比发展,最普遍的现象就是忙的设备不堪重负,闲的设备资源储备过多,二者相互之间又无法借用和共用。这是由于对底层网络建设是以功能单元为中心进行建设的,并不考虑上层业务对底层资源调用的优化,这
使得对网络的投入往往无法取得同样的业务应用效果的改善,反而浪费了较多的资源和维护成本。
l 服务策略不一致:传统架构最严重的问题是这种以孤立的设备功能为中心的设计思路无法真正从整个系统角度制订统一的服务策略,比如安全策略、高可用性策略、业务优化策略等等,造成跨平台策略的不一致性,从而难以将所投入的产品能力形成合力为上层业务提供强大的服务支撑。
因此,按传统底层基础设施所提供的服务能力已无法适应当前业务急剧扩展所需的资源要求,本次数据中心建设必须从根本上改变传统思路,遵照一种崭新的体系结构思路来构造新的数据中心IT基础架构。
2.2 XX数据中心目标架构
面向服务的设计思想已经成为Web2.0下解决来自业务变更、业务急剧发展所带来的资源和成本压力的最佳途径。从业务层面上主流的IT厂商如IBM、BEA等就提出了摒弃传统的“面向组件(Component)”的开发方式,而转向“面向服务”的开发方式,即应用软件应当看起来是由相互独立、松耦合的服务构成,而不是对接口要求严格、变更复杂、复用性差的紧耦合组件构成,这样可以以最小的变动、最佳的需求沟通方式来适应不断变化的业务需求增长。鉴于此,XX数据中心业务应用正在朝“面向服务的架构Service Oriented Architecture(SOA)”转型。与业务的SOA相适应,XX提出支撑业务运行的底层基础设施也应当向“面向服务”的设计思想转变,构造“面向服务的数据中心”(Service Oriented Data Center,SODC)。
传统组网观念是根据功能需求的变化实现对应的硬件功能盒子堆砌而构建企业网络的,这非常类似于传统软件开发的组件堆砌,被已经证明为是一种较低效率的资源调用方式,而如果能够将整个网络的构建看成是由封装完好、相互耦合松散、但能够被标准化和统一调度的“服务”组成,那么业务层面的变更、物理资源的复用都将是轻而易举的事情。SODC就是要求当SOA架构下业务的变更,导致软件部分的服务模块的组合变化时,松耦合的网络服务也能根据应用的变化自动实现重组以适配业务变更所带来的资源要求的变化,而尽可能少的减少复杂硬件的相关性,从运行维护、资源复用效率和策略一致性上彻底解决传统设计带来的顽疾。
具体而言SODC应形成这样的资源调用方式:底层资源对于上层应用就象由服务构成的“资源池”,需要什么服务就自动的会由网络调用相关物理资源来实现,管理员和业务用户不需要或几乎可以看不见物理设备的相互架构关系以及具体存在方式。SODC的框架原型应如下所示:
在图中,隔在物理架构和用户之间的“交互服务层”实现了向上提供服务、向下屏蔽复杂的物理结构的作用,使得网络使用者看到的网络不是由复杂的基础物理功能实体构成的,而是一个个智能服务——安全服务、移动服务、计算服务、存储服务……等等,至于这些服务是由哪些实际存在的物理资源所提供,管理员和上层业务都无需关心,交互服务层解决了一切资源的调度和高效复用问题。
SODC和SOA构成的数据中心IT架构必将是整个数据中心未来发展的趋势,虽然实现真正理想的SODC和SOA融合的架构将是一个长期的历程,但在向该融合框架迈进的每一步实际上都将会形成对网络灵活性、网络维护、资源利用效率、投资效益等等方面的巨大改善。因此XX本次数据中心的网络建设,要求尽可能的遵循如上所述的新一代面向服务的数据中心设计框架。
2.3 XX数据中心设计目标
在基于SODC的设计框架下,XX新一代数据中心应实现如下设计目标:
l 简化管理:使上层业务的变更作用于物理设施的复杂度降低,能够最低限度的减少了物理资源的直接调度,使维护管理的难度和成本大大降低。
l 高效复用:使得物理资源可以按需调度,物理资源得以最大限度的重用,减少建设成本,提高使用效率。即能够实现总硬件资源占用量降低了,而每个业务得到的服务反而更有充分的资源保证了。
l 策略一致:降低具体设备个体的策略复杂性,最大程度的在设备层面以上建立统一、抽象的服务,每一个被充分抽象的服务都按找上层调用的目标进行统一的规范和策略化,这样整个IT将可以达到理想的服务规则和策略的一致性。
2.4 XX数据中心技术需求
SODC架构是一种资源调度的全新方式,资源被调用方式是面向服务而非象以前一样面向复杂的物理底层设施进行设计的,而其中交互服务层是基于服务调用的关键环节。交互服务层的形成是由网络智能化进一步发展而实现的,它是底层的物理网络通过其内在的智能服务功能,使得其上的业务层面看不到底层复杂的结构,不用关心资源的物理调度,从而最大化的实现资源的共享和复用。要形成SODC要求的交互服务层,必须对网络提出以下要求:
2.4.1 整合能力
SODC要求将数据中心所需的各种资源实现基于网络的整合,这是后续上层业务能看到底层网络提供各类SODC服务的基础。整合的概念不是简单的功能增多,虽然整合化的一个体现是很多独立设备的功能被以特殊硬件的方式整合到网络设备中,但其真正的核心思想是将资源尽可能集中化以便于跨平台的调用,而物理存在方式则可自由的根据需要而定。
数据中心网络所必须提供的资源包括:
l 智能业务网络所必须的智能功能,比如服务质量保证、安全访问控制、设备智能管理等等;
l 数据中心的三大资源网络:高性能计算网络;存储交换网络;数据应用网络。
这两类资源的整合将是检验新一代数据中心网络SODC能力的重要标准。
2.4.2 虚拟化能力
虚拟化其实就是把已整合的资源以一种与物理位置、物理存在、物理状态等无关的方式进行调用,是从物理资源到服务形态的质变过程。虚拟化是实现物理资源复用、降低管理维护复杂度、提高设备利用率的关键,同时也是为未来自动实现资源协调和配置打下基础。
新一代数据中心网络要求能够提供多种方式的虚拟化能力,不仅仅是传统的网络虚拟化(比如VLAN、VPN等),还必须做到:
l 交换虚拟化
l 智能服务虚拟化
l 服务器虚拟化
2.4.3 自动化能力
自动化是SODC架构中上层自动优化的实现服务调用必须条件。在高度整合化和虚拟化的基础上,服务的部署完全不需要物理上的动作,资源在虚拟化平台上可以与物理设施无关的进行分配和整合,这样我们只需要将一定的业务策略输入给智能网络的策略服务器,一切的工作都可以按系统自身最优化的方式进行计算、评估、决策和调配实现。
这部分需要做到两方面的自动化:
l 网络管理的自动化
l 业务部署的自动化
2.4.4 绿色数据中心要求
当前的能源日趋紧张,能源的价格也飞扬直上;绿地(Green Field)是我们每个人都关心的议题。如何最大限度的利用能源、降低功耗,以最有效率方式实现高性能、高稳定性的服务是新一代的数据中心必须考虑的问题。
第3章 XX数据中心技术实现
根据以上新一代数据中心网络的技术要求,必须对传统数据中心所使用的常规以太网技术进行革新,数据中心级以太网(Data Center Ethernet,简称DCE)技术由此诞生。
DCE之前也被一些厂商称为汇聚型增强以太网技术(Converged Enhanced Ethernet,简称CEE),是兼容传统以太网协议并按新一代数据中心的传输要求,对其进行全面革新的一系列标准和技术的总称。因此,为达到XX的新一代数据中心的建设目标,必须摒弃传统以太网技术,而采用新一代的DCE(CEE)技术进行组网。
具体而言,本次XX数据中心所采用的DCE技术,可以达到以下的技术目标。
3.1
整合能力
3.1.1 一体化交换技术
DCE技术的重要目标是实现传统数据中心最大程度的资源整合,从而实现面向服务的数据中心SODC的最终目标。在传统数据中心中存在三种网络:使用光纤存储交换机的存储交换网络(Fiber Channel SAN),便于实现CPU、内存资源并行化处理的高性能计算网络(多采用高带宽低延迟的InfiniBand技术),以及传统的数据局域网。DCE技术将这三种网络实现在统一的传输平台上,即DCE将使用一种交换技术同时实现远程存储、远程并行计算处理和传统数据网络功能。这样才能最大化的实现三种资源的整合,从而便于实现跨平台的资源调度和虚拟化服务,提高投资的有效性,同时还降低了管理成本。
XX业务的特点不需要超级计算功能,因此本次项目要实现存储网络和传统数据网络的双网合一,使用DCE技术实现二者的一体化交换。当前在以太网上融合传统局域网和存储网络唯一成熟技术标准是Fiber Channel Over Ethernet技术(FCoE),它已在标准上给出了如何把存储网(SAN)的数据帧封装在以太网帧内进行转发的相关技术协议。由于该项技术的简单性、高效率、经济性,目前已经形成相对成熟的包括存储厂商、网络设备厂商、主机厂商、网卡厂商的生态链。具体的协议发布可参见 FCoE 的相关Web Sites。 (http://www.fcoe.com
http://www.t11.org/fcoe )
本次数据中心建设将做好FCoE的基础设施准备,并将在下一阶段完成基于FCoE技术的双网融合。
3.1.2
无丢弃以太网技术
为保证一体化交换的实现,DCE改变了传统以太网无连接、无保障的Best Effort传输行为,即保证主机在通过以太网进行磁盘读写等操作、高性能计算所要求的远程内存访问、并行处理等操作,不会发生任何不可预料的传输失败,达到真正的“无丢包”以太网目标。DCE在网络中以硬件及软件的形式实现了以下技术:
基于优先级类别的流控(Priority Flow Control)
通过基于IEEE 802.1p类别通道的PAUSE功能来提供基于数据流类别的流量控制
带宽管理
IEEE 802.1Qaz 标准定义基于IEEE 802.1p 流量类别的带宽管理以及这些流量的优先级别定义
拥塞管理
IEEE 802.1Qau 标准定义如何管理网络中的拥塞(BCN/QCN)
l 基于优先级类别的流控在DCE 的理念中是非常重要的一环,通过它和拥塞管理的相互合作,我们可以构造出“不丢包的以太网”架构;这对今天的我们来说,它的诱惑无疑是不可阻挡的。不丢包的以太网络提供一个安全的平台,它让我们把一些以前无法安心放置到数据网络上的重要应用能安心的应用到这个DCE的数据平台。
l 带宽管理在以太网络中提供类似于类似帧中继(Frame Relay)的带宽控制能力,它可以确保一些重要的业务应用能获得必须的网络带宽;同时保证网络链路带宽利用的最大化。
l 拥塞管理可以提供在以太网络中的各种拥塞发现和定位能力,这在非连接的网络中无疑是一个巨大的挑战;可以说在目前的所有非连接的网络中,这是一个崭新的应用;目前的研究方向主要集中在后向拥塞管理(BCN)和
量化拥塞管理(QCN)这两个方面。
3.1.3
性能支撑能力
为保证实现一体化交换和资源整合,DCE还必须对传统以太网的性能和可扩展性的进行革新。
首先为保证三网合一后的带宽资源,万兆以太网技术只是DCE核心层带宽的起点。而正在发展中的40G/100G以太网才是DCE技术将来的主流带宽。因此,要保证我们今天采购的设备能有5年以上的生命周期,就必须考虑硬件的可扩展能力。这也就是说从投资保护和工程维护的角度出发,我们需要一个100G平台的硬体设备,即每个设备的槽位至少要支持100G的流量(全双工每槽位200Gbps),只有这样才能维持该设备5年的生命周期。同时从经济性的角度来考虑,如果能达到400G的平台是最理想的。
另外存储网络和高性能计算所要求的通过网络实现的远程磁盘读写、内存同步的性能需求,DCE设备必须提供比传统以太网设备低几个数量级的端口间转发延迟。DCE要求的核心层的三层转发延迟应可达到30us以下,接入层的二层转发延迟应可在3~4us以下。这都是传统以太网技术无法实现的性能指标要求。
3.1.4 智能服务的整合能力
众所周知,应用的复杂度是在不断的提升,同时伴随着网络的融合,应用对网络的交互…可以预见的是网络的复杂度也将不断的提升。这也印证我们的判断:应用对网络的控制将逐步增强,网络同时也在为应用而优化。
因此构建一个单业务的简单L2转发网络并不是网络设备的设计方向;全业务的设备和多业务融合的网络才是我们所需要的环境。
那么我们需要什么样的全业务呢,很明显Data Center Ethernet 是一个必备的项目,同时我们至少还需要其它的基本业务属性来保障一个多业务网络的运行,如:
l 服务质量保证
QoS
l 访问列表控制
ACL
l 虚拟交换机的实现
Virtual Switch
l 网络流量分析
Netflow
l CPU抗攻击保护
CoPP
l 远程无人值守管理 CMP
l 嵌入式事件管理
EEM
当然,所有这些业务的实现都是在不影响转发性能的前提条件下的。失去这个大前提,多业务的实现就变得毫无意义。
所以设计一个好的产品就必须顾全多业务、融合网络这个大前提。如何使这些复杂的业务处理能够在高达100G甚至是400G的线路卡上获得线速处理的性能是考验一个硬件平台的重要技术指标。
最终的胜出者无疑就是能够用最小的代价来换取最大业务实现和性能的设备平台。
3.2
虚拟化能力
DCE对网络虚拟化不仅仅是传统意义上的VLAN和VPN,为实现SODC的交互服务层资源调度方式,DCE还能够做到以下的虚拟化能力。
3.2.1 虚拟交换技术
虚拟交换技术可以实现当我们使用交换机资源时,我们可以不用关心交换服务的物理存在方式,它可能是由一台交换机提供,也可能是两台交换机设备,甚至可以是一个交换机中的几个虚拟交换机之一。思科的DCE技术就提供了将两个物理交换机虚拟为一台交换机的虚拟交换系统(VSS)技术,以及将一个交换机虚拟化为多个交换机的虚拟设备(VDC)技术。
(一)虚拟交换系统(VSS)
VSS技术可将网络的双核心虚拟化为单台设备,比如使用的Cisco 6509的9插槽设备将完全被虚拟化成为单台18槽机箱的虚拟交换机。虚拟交换机性能倍增、管理复杂度反而减半。具体有如下优势:
l 单一管理界面:管理界面完全为单台设备管理方式,管理和维护工作量减轻一半;
l 性能翻倍:虚拟交换系统具备两台叠加的性能,与其它交换机通过跨物理机箱的双千兆以太网或双万兆以太网捆绑技术,远比依靠路由或生成树的负载均衡更均匀,带宽和核心吞吐量均做到真正的翻倍。
l 协议简单:虚拟交换系统与其它设备间的动态路由协议完全是单台设备与其它设备的协议关系,需维护的路由邻居关系数以二次方根下降,在本系统中可达4~5倍下降,工作量和部署难度大大降低;虚拟交换系统同时作为单台设备参与生成树计算关系,生成树计算和维护量以二次方根下降,在本系统中可达4~5倍下降,工作量和部署难度大大降低。
l 冗余可靠:虚拟交换系统形成虚拟单机箱、物理双引擎的跨机箱冗余引擎系统,下连接入交换机原来需要用动态路由或生成树实现冗余切换的,在VSS下全都可以用简单的链路捆绑实现负载均衡和冗余,无论是链路还是引擎,冗余切换比传统方式更加迅捷平滑,保持上层业务稳定运行。以前两个单引擎机箱的其中一台更换引擎,一定会导致数据的丢失,而虚拟交换系统里任意一台更换引擎,数据可以保证0丢失。
(二)虚拟设备系统(VDC)
VDC技术则可以实现将一台交换机划分为多个虚拟的子交换机,每个交换机拥有独立的配置界面,独立的生成树、路由、SNMP、VRRP等协议进程,甚至独立的资源分配(内存、TCAM、转发表等等)。它与VSS配合,将在实现更加灵活的、与物理设备无关的跨平台资源分配能力,为数据中心这种底层设施资源消耗型网络提供更经济高效的组网方式,也为管理和运营智能化自动化创造条件。
物理设备虚拟成若干个逻辑上的独立设备的图示:
3.2.2 网络服务虚拟化
在服务资源整合以及设备虚拟化的基础之上,DCE要求每个虚拟化的网络应用区都有自己的业务服务设施,比如自己的防火墙、IDS、负载均衡器、SSL加速、……网络服务,这些如果都是物理上独占式分配的,将是高成本、低效率且难于维护管理的。DCE网络在提供这些网络智能服务时都可以以虚拟化的方式实现各类服务的资源调用,思科的DCE网络中就可以实现虚拟防火墙、虚拟IDS、虚拟负载均衡器、虚拟SSL VPN网络……等等,从而实现网络智能服务的虚拟化。
3.2.3 服务器虚拟化
服务器虚拟化可以使上层业务应用仅仅根据自己所需的计算资源占用要求来对CPU、内存、I/O和应用资源等实现自由调度,而无须考虑该应用所在的物理关联和位置。当前商用化最为成功的服务器虚拟化解决方案是VMWare的VMotion系列,微软的Virtual Server和许多其它第三方厂商(如Intel、AMD等)也正在加入,使得服务器虚拟化的解决方案将越来越完善和普及。
然而人们越来越意识到服务器虚拟化的系统解决方案中除了应用、主机、操作系统的角色外,网络将是一个更为至关重要的角色。网络将把各个自由联系成为一个整体,网络将是实现自由虚拟化的桥梁。服务器虚拟化需要DCE能够提供以下能力:
l 资源的整合:业务应用运行所依赖的物理计算环境都需要网络实现连接,然而在传统网络中,传输数据的数据网、互连CPU和内存的计算网、互连存储的存储网都是孤立的,这就无法真正实现与物理无关的服务器资源调度,因此实现真正意义上彻底的服务器虚拟化,前面提到的DCE三网一体化交换架构是必须的条件。
l 网络的虚拟机意识:传统网络是不具备虚拟机意识的,即在网络上传递的信息是无法区别它是来自于哪个虚拟机,也无法在网络上根据虚拟机来提供相应的网络服务,当虚拟机迁移,也没有相应的网络跟踪手段保证服务的全局一致性。不过这些都是DCE正在解决的问题,一些DCE的领导厂商,比如思科,已经在推出的商用化DCE产品中提供了相应的虚拟机标识机制,并且思科已经联合VMware等厂商将这些协议提交IEEE实现标准化。
l 虚拟机迁移的网络环境:服务器虚拟化是依靠虚拟机的迁移技术实现与物理资源无关的资源共享和复用的。虚拟机迁移需要一个二层环境,这导致迁移范围被局限在传统的VLAN内。我们知道Web2.0、云计算等概念都需要无处不在的数据中心,那么如何实现二层网络的跨地域延展呢?传统的L2 MPLS技术太复杂,于是IEEE和IETF正在制定二层多路径(即二层延展)的新标准,DCE的领导厂商思科公司也提出了一种新的协议标准Cisco Over the Top Virtualization(OTV)来解决跨城域或广域网的二层延展性问题,从而为服务器虚拟化提供可扩展的网络支撑。
3.3
自动化
自动化是SODC架构中上层自动优化的实现服务调用必须条件。在高度整合化和虚拟化的基础上,服务的部署完全不需要物理上的动作,资源在虚拟化平台上可以与物理设施无关的进行分配和整合,这样我们只需要将一定的业务策略输入给智能网络的策略服务器,一切的工作都可以按系统自身最优化的方式进行计算、评估、决策和调配实现。现在商用的DCE自动化解决方案包括管理自动化和业务部署自动化。
XX数据中心将在后续的建设中逐步完善自动化管理和自动化业务部署,但需要在本期通过DCE技术的实施打下未来自动化部署的坚实基础。
3.4
绿色数据中心
DCE技术的整合化、虚拟化和自动化本身就是在达到同样业务能力的要求下实现高效率利用硬件资源、减少总硬件投入、节约维护管理成本等方面的最佳途径,这本身也是绿色数据中心的必要条件。
另外DCE产品必须在硬件实现上实现低功耗、高效率,包括
l 利用最新半导体工艺 (越小纳米的芯片要比大纳米的芯片省电)
l 降低逻辑电路的复杂度
(在接入层使用二层设备往往要比三层设备省电)
l 减少通用集成电路的空转 (使用定制化的专业设计的芯片往往比通用芯片省电)
l 等等……
由此可见,对于一台网络设备,在业务能力相当的前提条件下,越小的功耗就代表越先进的技术。在DCE设备一般可以做到维持三层的全业务万兆吞吐功耗小于25W、二层的万兆吞吐功耗小于13W。
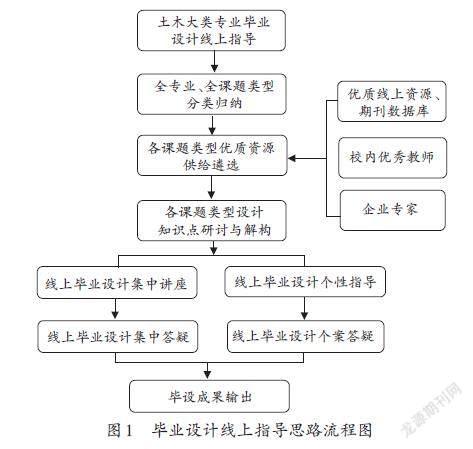
第4章 XX云计算平台网络设计
4.1
总体网络结构
本次XX数据中心网络的建设将采用新一代的DCE技术,并使用DCE技术的代表厂商Cisco公司的Nexus系列产品。网络结构将采用大型数据中心典型的层次化、模块化组网结构。
(插入总体图)
4.1.1 层次化结构的优势
采用层次化结构有如下好处:
l 节约成本:园区网络意味着巨大的业务投资正确设计的园区网络可以提高业务效率和降低运营成
本。
l 便于扩展:一个模块化的或者层次化的网络由很多更加便于复制、改造和扩展的模块所构成,在添
加或者移除一个模块时,并不需要重新设计整个网络。每个模块可以在不影响其他模块或者网络核心的情况下投入使用或者停止使用。
l 加强故障隔离能力:通过将网络分为多个可管理的小型组件,企业可以大幅度简化故障定位和排障处理时效。
4.1.2 标准的网络分层结构
层次化结构包括三个功能部分,即接入层、分布层和核心层,各层次定位分别如下:
l 核心层:是企业数据交换网络的骨干,本层的设计目的是实现快速的数据交换,并且提供高可靠性和快速的路由收敛。
l 分布层:也称为汇聚层。主要汇聚来自接入层的流量和执行策略,当第三层协议被用于这一层时可以获得路由负载均衡,快速收敛和可扩展性等好处。分布层还是网络智能服务的实施点,包括安全控制、应用优化等智能功能都在此实施。
l 接入层:负责提供服务器、用户终端、存储设施等等的网络第一级接入功能,另外网络智能服务的初始分类,比如安全标识、QoS分类将也是这一层的基本功能。
4.1.3 XX云计算平台数据中心网络结构
根据业界企业网络最佳设计实践参考,在边缘节点端口较少的小型网络中,可以考虑将核心层与分布层合并,小型网络的网络规模主要由接入层交换机决定。但对于XX而言,结合XX的业务现状及发展趋势,我们可以看到未来几年内业务处于一个高速成长期,必须在本期网络架构中充分考虑未来的可扩展性。所以XX企业内部核心网络层次结构必须具有以上严格清晰的划分,即具有清晰的核心层、会聚分布层、接入层等分层结构,才能保证网络的稳定性、健壮性和可扩展性,以适应业务的发展。
XX的业务应用特点又决定了核心层将相对接入的网络模块较少,只有楼层汇聚接入、数据中心汇聚接入、广域网接入等三块,如果采用单独的大容量物理核心设备将造成浪费,而如果采用低端核心设备则会对业务相对繁忙的数据中心汇聚形成瓶颈,也影响网络整体的稳定性。鉴于此,我们采用超大规模核心层设备Cisco Nexus 7000作为核心,但虚拟化为两套交换机,一套用于全网核心,一套用于数据中心汇聚。这样做的优势如下:
l 逻辑上仍然是清晰的两套设备,完全保持了前述网络分层结构的优势。
l 在性能上实现了网络核心和数据中心汇聚交换机资源的共享和复用,非常好的解决了核心层数据量和数据中心数据量可能存在较大差异的问题。
l 以较低的投入升级了数据中心汇聚交换机的能力(相当于可以与核心层复用4Tbps以上的交换能力),适于下一阶段要进行的数据中心双网融合的资源需求。
l 减少了设备数量,降低了设备投入成本、功耗开销和维护管理的复杂度。
XX新一代数据中心整体网络结构如下图所示:
4.2
数据中心核心层设计
本次我们采用能扩展到15Tbps以上的Cisco Nexus 7000系列大型DCE交换机,每台Nexus7000划分为两个VDC(虚拟交换机),一个虚拟交换机作为XX数据中心核心,另一个虚拟交换机作为数据中心的分布汇聚层交换机。
我们选择的是10插槽Nexus7010,以双机双冗余方式部署在网络核心。每台当前支持的最大交换容量为4Tbps,最大万兆端口容量为256个,每插槽交换能力为230Gbps(未来可扩展到500Gbps以上),可以在未来扩展40G/100G以太网。
本次每台N7010暂配32个万兆端口,48个千兆端口,这些端口都可在物理上划分为属于全网核心的虚拟交换机和属于数据中心汇聚的虚拟交换机,每个虚拟交换机从软件进程到配置界面都各自独立,但可以共享和复用总的交换机资源。
每个虚拟交换机都支持vPC技术(Virtual Port-Channel),即可以实现跨交换机的端口捆绑,这样在下级交换机上连属于不同机箱的虚拟交换机时,可以把分别连向不同机箱的万兆链路用与IEEE 802.3ad兼容的技术实现以太网链路捆绑,提高冗余能力和链路互连带宽的同时,大大简化网络维护。
核心层虚拟交换机与其它设备互连都采用路由端口和三层交换方式,因此采用vPC进行链路捆绑时使用三层端口链路捆绑技术。如图所示:
4.3
数据中心分布层设计
4.3.1 数据中心分布层虚拟交换机
数据中心的分布汇聚层交换机是采用上述Nexus 7010内单独划分处理的虚拟交换机实现。虚拟交换机之间通过外部互连,并同样采用vPC的三层端口链路捆绑技术。分布汇聚层虚拟交换机与下面的接入层采用二层端口的vPC跨机箱捆绑技术互连,如下图所示。
4.3.2 数据中心分布层智能服务机箱
数据中心的网络智能服务由设计在分布层的智能服务机箱提供(Multi-Services Chassis)。单独的服务机箱可以不破坏高性能的一体化交换架构形成的数据中心主干,有选择的对三网合一的数据中心流量提供按需的网络智能服务。比如本地存储流量没有必要在传输过程中经过数据应用类防火墙的检查(存储网内有自己的安全访问控制机制),这样的设计比较容易实现类似的FCoE流量的无干扰直达。
智能服务机箱采用Cisco Catalyst 6500交换机,暂配置720G引擎和18个万兆端口,内置防火墙模块(FWSM)、应用控制模块(ACE), 提供应用级安全访问控制和应用优化、负载均衡功能。
智能服务机箱采用双机冗余结构,利用Catalyst 6500的VSS虚拟交换机功能,两个独立的机箱完全可以看成为一个逻辑机箱,再通过共4个万兆上连至2个N7000上的分布汇聚层虚拟交换机上。VSS技术形成了一个具有1.44Tbps能力的智能服务机箱,再通过N7000的vPC技术,则形成了智能服务机箱和N7000之间全双工高达80Gbps的互连带宽。由于N7000和6500VSS上都预留了足够的万兆端口,这个捆绑带宽值根据未来智能服务处理性能的需要还可以成倍的平滑升级。物理和逻辑的连接示意图如下面所示。
物理结构图
逻辑结构图
在一期实施中,智能服务机箱内智能服务器硬件模块的部署密度不高——每个机箱内防火墙模块、负载均衡模块各一块,这样每个机箱内使用引擎加速技术的防火墙模块最大迸发吞吐量32Gbps,负载均衡模块最大四层吞吐能力16Gbps(而且不是所有都需要负载均衡),完全满足当前业务需求,因此可以在实施中简化配置,改双机箱VSS结构为一主一备机箱方式,在以后随业务需求上涨,业务模块增多,再完善为双
机箱负载均衡的VSS模式。
由于服务机箱内的防火墙模块和应用控制优化模块都支持虚拟化技术,因此还可以利用智能服务虚拟化实现基于每个数据中心业务组的定制服务策略和功能,使每个业务应用使用所需资源时不必过度关注其物理存在方式,从而实现与物理无关的跨平台智能服务调用(SODC的交互服务调用),极大的提高资源利用效率,减少了物理设施维护的复杂度。这部分将在后面智能服务的详细设计中加以阐明。
4.4
数据中心接入层设计
使用Cisco Nexus 5000和2000系列DCE接入交换机,可以实现数据中心接入层的分级设计。
本次建议XX使用的是具有将近1.2Tbps交换能力、初始配置有40个万兆以太网端口的Nexus 5020交换机,以及具备48个10/100/1000M以太网端口、4个万兆上连端口的Nexus 2148T。Nexus 2000是5000系列的交换矩阵延展器,通过部署在柜顶(Top of the Rack,ToR)的2148T,可以将本地接入的高密度服务器上连到5020,4个上连万兆端口可以提供48个千兆端口中至少40个端口的全线性转发能力,通过连接多台2148T,5020可以将1.2T的惊人交换能力延展到多个机柜,实现高性能、高密度、低延迟的DCE服务器群接入能力。而且作为5020的延展设备,2148T无需自身进行复杂配置,所有管理和配置都可在其上游的5020上完成,大大简化了多机柜、高密度服务器接入设备的管理复杂度。
Nexus 5000和2000都是按柜顶(Top of the Rack,ToR)交换机的尺寸设计,1~2U的高度内紧凑的集成了高密度的DCE端口,但同时提供可热插拔的冗余风扇组和冗余电源系统,其可靠性远非其它传统以太网中固定接口小交换机所可比。
Nexus 5000是业界第一款商用化FCoE交换机,其所有万兆以太网端口都支持FCoE。同时Nexus 5000支持扩展16个1~4G Fiber Channel端口或8个1~8G Fiber Channel端口,完全支持Fiber Channel SAN交换机的完整功能特性。也即传统需要以太网卡、FC存储卡(HBA)、InfiniBand卡的主机,只需要一张FCoE的以太网卡(CNA)就可以实现三种网络的接入,用户在操作系统上也可以看见虚拟化的以太网卡、HBA卡和InfiniBand卡,而它们共享万兆的高带宽,Nexus 5000还可通过Fiber Channel接口连接传统的SAN网络,实现SAN/LAN的整合,通过这种整合和虚拟化实现资源的自由调度和最大化利
用,同时成倍减少的网卡数节约了功耗,提高了可靠性,降低了维护成本。
XX的主机、服务器机柜可分为两列,每列选两个列中柜(Middle of the Row),柜内部署Nexus 5020,而每列其它普通机柜在柜顶(ToR)放置Nexus 2148T。物理部署类似下图所示:
普通的机柜内放置千兆端口服务器,每机柜可容纳具有冗余网卡的千兆服务器高达20个。每列的两个列中柜(MoR)内可放置具备万兆以太网卡的高性能服务器、万兆FCoE卡的新型服务器、具备Fiber Channel卡(HBA)的服务器和SAN交换机,甚至将来可以扩展具备FCoE接口的盘阵。
提供两种实际物理接线的方法:
方法1:交叉冗余链接
每两个普通机柜的设备都与另一个机柜的Nexus 2148T冗余交叉上连,每个普通机柜柜顶(ToR)的Nexus 2148T又通过4个万兆交叉上连至本列的两个列中柜(MoR)内的Nexus 5020,每列两个列中柜(MoR)内的Nexus 5020冗余互连,并且再交叉上连至Nexus 7000的虚拟交换机上。物理连接类似下图所示:
方法2:以Nexus 5000为单位的冗余和负载均衡
这种方法保证对于每个Nexus 2000而言只连接一个Nexus 5000,避免跨越Nexus 5000的负载均衡,也即避免负载均衡时偶发的在两个Nexus 5000互连的链路上产生流量。这种方法的优点是负载均衡效果更好,避免两个Nexus 5000之间可能产生的拥塞(虽然可能性比较小),而且网络结构简单,易于管理。但缺点是冗余能力不如方法1,
由于方法1让每一个Nexus 2000交错连接,所以可以容忍2000、5000同时出现故障。
由于2000、5000同出故障的概率极低,而方案2更容易实施,管理复杂度更小,所以推荐使用方法2。
在服务器的分配应尽量遵循相互业务紧密、访问量大或需要相互进行虚拟机迁移和调度的物理服务器应放置在同一柜列(Row)的原则,即共用一对Nexus 5000。
上图每个机柜的20台服务器可以完全实现双网卡的Load Balance Teaming方式下的线性网络接入,即每台服务器2G带宽(4G吞吐量)的网络接入能力。在一期实施中,为简化服务器端设计,可以服务器网卡可以先采用Active/Standby的Teaming方式。
第5章
应用服务控制与负载均衡设计
5.1
功能介绍
5.1.1 基本功能
本项目我们在数据中心的分布汇聚层的智能服务机箱内配置了Cisco 应用控制模块 (Application Control Engine, ACE),作为数据中心的重要网络智能服务,该模块可为后台应用服务器提供高性能表现和最高级别的体系控制和安全保护。ACE主要针对大型企业和电信用户的服务器集群环境,可以有效地对重要应用数据的传送进行优化和简化,同时具备良好的性价比。
ACE提供了如下的性能和功能:
l ACE 提供四到七层数据包的内容交换和负载均衡功能,为服务器机群提供虚拟地址和端口。ACE在插入Catalyst 6500后,交换机上的所有端口即可成为四层交换端口。ACE与Catalyst 6509数据总线和交换矩阵都有连接,最高带宽为16Gbps,每秒连接数为345000个。ACE不仅为服务器提供负载均衡,还可为外部的防火墙、VPN集中器……等等网络服务设施提供负载均衡。
l ACE具备资源分配和隔离功能,是服务器虚拟化的重要手段之一。在一个物理模块中,ACE可以划分为多个独立的分区,每一个分区都可以分配给一个应用或者一个用户使用。另外,每一个分区都支持层次化的管理模式,提供了资源管理的灵活性和安全性。ACE支持基于角色的访问控制
(role-based access control), 所有的用户都被分配了相应的角色(role),每个角色在分区内被允许执行相关的命令集。例如系统管理员角色(system admin role)可以执行ACE所有的命令而应用程序管理员角色(application admin role)只能执行和后台应用及内容交换的命令等。
l ACE具有强大的安全功能,可以有效地保护后台的应用程序免受恶意攻击。主要的技术包括: HTTP深层包检测、双向动态、静态和基于策略的地址转换(NAT/PAT),访问控制列表、TCP包头验证、TCP连接状态监控等。
l ACE支持多层次的冗余性,对关键业务提供最高等级的可用性保护。ACE是目前业界唯一可以实现以下三种高可用性保护的四层交换机
n 机箱间冗余 --- 两台机箱间的ACE板卡可互为冗余保护
n 板卡间冗余 --- 同一机箱内的多个ACE板卡可互为冗余保护
n 虚拟分区前冗余 –同一ACE板卡内的不同虚拟分区之前可互为保护
l ACE的冗余保护对动态的连接进行保护,保证当主业务板卡故障时业务连接仍然得以保持。
l 硬件加速方式的协议控制,对常见协议提供有效的检查、过滤和绑定。
这些协议包括HTTP,RTSP,DNS,FTP,ICMP等。硬件方式实现ACL和NAT功能,最多支持一百万个NAT转换表项。
5.1.2 应用特点
5.1.2.1. 虚拟化分区
虚拟分区实现了资源分段和隔离,使思科ACE可作为一个物理模块中的多个独立虚拟模块运行。凭借这个解决方案,企业能够利用一个思科ACE模块,为多达250个不同的企业机构、应用、或客户和合作伙伴提供事先定义的服务水平。虚拟分区使应用基础设施能更好地用于业务运营,同时减少设备并实现出色的控制。
另外,每个虚拟分区还包括分级管理域,既能确保应用的性能水平,又可使ACE模块中的可用资源得到最大限度的利用。
思科ACE为分散的管理提供集中的控制,从而为每个虚拟分区提供了基于模板的或可自定义的用户访问权限。基于角色的访问控制(Role Based Access Control, RBAC)特性允许企业对管理角色进行定义,限定管理员对模块或虚拟分区内特定功能的使用权。由于一个机构中可能有多位管理员需要以不同级别(例如,应用管理、服务器管理、网络管理、安全管理等)与思科ACE模块互动,因此,对这些管理角色进行准确定义,使每个管理员群组都能够在不影响其他群组的情况下顺利地执行任务,无疑是一项重要工作。
通过与Cisco Catalyst 6500的虚拟路由转发(VRF)、防火墙模块的虚拟化相集成,可支持从路由功能、防火墙到应用控制负载均衡的端到端的智能服务虚拟化(如下图所示)。
5.1.2.2. 性能和扩展性
思科ACE提供了业界最高水平的应用供应能力。每个思科ACE模块的吞吐率可高达16 Gbps,每秒支持345,000个持续连接,可以轻松地处理大量数据文件、多媒体应用和庞大的用户群体。ACE系列模块配备了“随增长而投资”的付费许可证,提供了最高16 Gbps的可扩展吞吐率,客户无需为扩充容量而全面升级系统。在设计上,ACE也为未来的增值服务和扩展功能预留了空间。实际上,通过在单一Cisco Catalyst 6500机箱中安装四个ACE模块,它提供了业界最高水平的可扩展性。
思科ACE还提供了多层冗余性、可用性和可扩展性,为您的关键业务提供最大限度的保护。它还是业内唯一提供三种高可用性模式的产品:
l 机箱间高可用性:一台Cisco Catalyst 6500中的ACE由对等Cisco Catalyst 6500中的ACE保护。
l 机箱内高可用性:Cisco Catalyst 6500中的一个ACE由同一Cisco Catalyst 6500中的另一个ACE保护(Cisco Catalyst 6500内置了强大的冗余性)。
l 分区之间高可用性:思科ACE支持在两个模块上配置的虚拟分区之间的高可用性,使特定分区能够在不影响模块中其他分区和应用的基础上执行故障切换。
所有这些可用性模式均通过复制连接状态和连接表,提供了快速的状态化应用冗余性。
5.1.2.3. 安全功能
思科自防御网络提供了多个级别的防御功能,使客户可以高枕无忧。思科ACE可通过以下特性,保护数据中心和关键应用免受恶意流量的影响:
l HTTP深度包检测——HTTP报头、URL和净负荷
l 双向网络地址转换(NAT)和端口地址转换(PAT)
l 支持静态、动态和基于策略的NAT/PAT
l 访问控制列表(ACL)可选择地允许端口间的哪些流量通过
l TCP连接状态跟踪
l 用于UDP的虚拟连接状态
l 序列号随机生成
l TCP报头验证
l TCP窗口尺寸检查
l 在建立会话时检查单播反向路径转发(URPF)
5.1.2.4. 集成硬件加速协议控制功能
在应用供应领域尚属首次面世,为许多常用数据中心协议,如HTTP、实时流协议(RTSP)、域名系统(DNS)、 FTP和互联网控制消息协议(ICMP),提供了有效的检测、过滤和修复功能。
拥有多达256,000个条目的大型可扩展ACL能够同时支持应用希望获得的前端可扩展性(用户/客户端应用数量)和后端可扩展性(服务器/服务器群数量)。此外,多达1,000,000个条目的高性能、可扩展NAT事件处理功能也支持许多大型数据中心的整合和应用更快速的面世。虚拟分区则可以使所有重叠的IP子网保持独立,无需为保护数据中心而进行费用高昂的网络重新设计、重新配置,或添加额外的设备。
思科ACE也支持对于协议符合性的检查,且可为安全分析提供事件记录和报告。
5.1.2.5. 基础设施简化
第二至七层网络集成——作为Cisco Catalyst 6500机箱的一个模块,思科ACE可以轻松地插入任何新型或现有的网络,提供了一个第二至七层全面而丰富的解决方案。该解决方案支持Catalyst 6500所支持的所有端口类型和数量,支持高达720 Gbps的机箱吞吐率,可以轻松扩展,来满足最大型网络的要求,此外,该集成解决方案也节省了所占空间。利用路由状态注入 (RHI)和自动状态集成,可支持应用和数据中心高可用性,而ACE虚拟分区通过开启或关闭网络中的物理接口可强制进行故障切换。
5.1.2.6. 功能整合
通过在一台设备上整合内容交换、SSL加速、数据中心安全等功能,思科ACE获得了从bps到pps的性能显著提升,缩短了应用延迟。利用功能整合,TCP信息流只需终结一次,而无需在网络上的四个或四个以上的位置进行终结,既节省了时间,又减少了处理工作和内存占用。加密和解密、负载均衡决策、安全性检查和业务策略分配及验证均在网络中的单一地点完成,以较少的设备、简化的网络设计和更方便的管理,实现了更理想的应用性能。
5.1.2.7. 管理功能
思科ANM可对多个ACE模块上的虚拟分区和层次化管理域进行管理。这个基于服务器的管理套件能对多个ACE模块上的大量虚拟分区进行发现、配置、监控和报告,使部署完全透明化。基于模板的配置和审计与服务激活/中止功能相配合,可快速实施应用。通过匹配服务API,可配置任务的RBAC组,允许多位管理员群组在多个ACE模块和虚拟分区上同时进行操作。
5.1.2.8. SSL加速
思科ACE解决方案集成了SSL加速技术,可卸载外部设备(服务器、设备等)的SSL流量加密和解密工作,允许思科ACE对加密数据进行更深入的检查,并应用安全和内容交换策略。这一设置不仅使思科ACE可以作出更明智的策略决策,还可确保您的应用供应平台遵守内部和外部法规。利用重加密功能,思科ACE解决方案在确保敏感数据端到端加密的同时,还可执行智能策略。
5.1.2.9. 事务处理可视性
凭借每秒处理350,000个系统日志的业界领先速度,思科ACE解决方案可记录大量连接设置和断接,它提供了事务处理级可视性,且不会影响数据传输性能。
5.1.2.10. 开放的硬件平台
利用两个可现场升级的子卡插槽,未来的需要硬件化处理的新功能都可作为子卡插入ACE模块,思科ACE模块能支持未来的功能和更高可扩展性。这种灵活性确保了思科ACE解决方案在今后的若干年中,都可以随着需求的发展而扩展,无需实施全面的模块升级,且几乎或完全不会造成业务中断。
5.2 应用优化和负载均衡设计
5.2.1 智能服务机箱设计
5.2.1.1. 物理连接
ACE模块和防火墙模块是一期数据中心实施中服务机箱提供的两个主要网络智能功能设备。在未来理想的设计蓝图中,两个服务机箱将通过VSS技术合并为虚拟的单一机箱,并同时实现内部服务模块的冗余和负载均衡。而在本期中,由于服务机箱内智能服务器硬件模块的部署密度不高——每个机箱内防火墙模块、负载均衡模块各一块,这样每个机箱内使用引擎加速技术的防火墙模块最大迸发吞吐量32Gbps,负载均衡模块最大四层吞吐能力16Gbps(而且不是所有都需要负载均衡),完全满足当前业务需求,因此可以在实施中简化配置,改双机箱VSS结构为一主一备机箱方式,在以后随业务需求上涨,业务模块增多,再完善为双机箱负载均衡的VSS模式。如下图所示:
每个机箱双万兆上连到两台Nexus 7000,建议如果有富余万兆端口可以每台使用4个万兆端口、双双上连到Nexus 7000,这样在Nexus 7000使用vPC跨机箱捆绑技术后,整个拓扑将可用看成是一个三角形结构——每个智能服务机箱上连带宽40G(双工80G),服务机箱之间带宽20G(双工40G)。
5.2.1.2. 逻辑结构
根据前面分析的数据中心业务特点,可以将数据中心划分为n个业务区,每个业务区将有自己独立的智能网络服务策略,比如对应独立的虚拟防火墙,对应独立的虚拟ACE,对应独立的虚拟路由VRF和虚拟局域网组VLAN Group。每个业务区在管理员给定的许可资源范围内充分共享和复用底层资源,以最低的管理和成本代价实现高效复用。如下图所示:
虚拟服务区划分的原则如下:
n 建议一个安全域对应一个虚拟服务区,这样每个虚拟防火墙的策略将可用简单化为入策略和出策略(安全设计章节将详细介绍)
n 虚拟防火墙、虚拟ACE、VRF、VLAN组一一对应是最理想化的虚拟化模式,这样将最大程度的实现与特定业务相关的从路由到应用、再到安全的一整套虚拟化资源划分策略
n 同一业务一定要在一个虚拟服务区中
n 需要进行虚拟机迁移的虚拟主机要在一个虚拟服务区中
n 划分不宜过细,分区不宜过多,建议一期不超过5个分区
服务机箱相互之间、与Nexus 7000之间的链路都采用二层交换方式,万兆在捆绑后使用IEEE 802.1Q封装,通过VLAN标记使不同的VLAN Group对应到机箱内不同的虚拟化服务上去。
上面的逻辑结构对应到前述的三角形拓扑中会看到一个冗余的环路,在二层结构中将会导致生成树算法而关闭冗余链路,我们建议将IEEE 802.1Q的VLAN Trunking链路上进行VLAN范围设置,使服务机箱互连的捆绑链路上的VLAN和每个服务机箱上连Nexus 7000的VLAN不同,前者的VLAN只用于服务模块相互间状态、配置同步和故障时的临时通道,这样所有链路都会被充
分利用,而也不会形成环路并需要生成树算法收敛计算路径。
5.2.2 应用负载均衡的设计
ACE的核心功能是负载均衡服务,在一般设计中有两种提供负载均衡服务的方式:串联模式和单臂模式。
以下为简单起见,只对Active部分进行描述,Standby部分的设计与Active部分完全相同,只有在Active局部或全部失效,才会由Standby来局部或全部接管,在后面“高可用性设计”部分有详细讨论。
5.2.2.1. 方案一:串联模式的应用负载均衡模块ACE
应用负载均衡模块ACE和防火墙模块FWSM均以串连方式在网络中部署。在桥接模式下串联部署的ACE非常简单,因为VIP(Virtual IP)直接位于客户端和服务器间的路径上。
在串联模式ACE设计方案中,发往VIP的客户端流量到达MSFC,MSFC执行IP路由查询,然后将流量转发至FWSM。FWSM做安全控制策略后再将其转发给ACE以作出负载均衡决策。选择真实服务器后,ACE执行L2重写(服务器NAT)并将流量转发至真实服务器。真实服务器发出的返回流量通过相同的路径回到客户端。如下图所示。
串联模式ACE的方案的特点:
n 比较容易做到虚拟防火墙、虚拟负载均衡理想的一一对应(如上图)
n FWSM 放置在ACE和MSFC之间,不能利用ACE的路由动态插入RHI功能(RHI后面将有介绍)
n 要在不同子网上实现新服务器群的负载均衡,要在ACE上添加新的服务器VLAN和客户端VLAN
n 服务器备份等发往WEB服务器的非负载均衡流量也都必须桥接通过ACE。
n 其它没有负载均衡必要的服务器通信都必须通过ACE进行
5.2.2.2. 方案二:单臂模式的应用负载均衡模块ACE
在单臂模式ACE设计方案中,ACE仅通过一个VLAN连接到MSFC,并处于防火墙保护之外。
从客户端发往VIP地址的流量即需要负载均衡的流量从MSFC路由到ACE,ACE进行负载均衡后,选择真实服务器后,执行L3重写(服务器NAT),并将流量转发到FWSM进行包检查,然后再转发到真实服务器。在MSFC上配置PBR时,FWSM将发自真实服务器的返回流量转发到MSFC。PBR对流量进行分类,随后将其发回ACE。ACE为服务器NAT执行反向L3重写,将流量发回MSFC,MSFC再将其转发回客户端。ACE单臂VLAN的默认网关是MSFC接口IP,真实服务器的默认网关则是FWSM上的接口IP。FWSM上定义了默认路由来将服务器流量转发到MSFC。
ACE单臂模式下,为了确保返回的流量能够回到ACE,需要NAT或策略路由(PBR),源NAT比较简单,但不适合使用源IP地址追踪客户端使用模式来进行记账和计费的客户。PBR避免了这一问题,但又带来了其他问题,如路由复杂性、非负载均衡流量的非对称路由和VRF支持等问题。
单臂模式ACE方案的特点:
n 最大的优势是可以对需要负载均衡的流量才经过ACE,这样大大提高了数据中心的可扩展性
n 可以配置RHI来动态地将VIP作为主机路由发布给MSFC,简化配置,实现动态学习
n 没有FWSM的保护,但对于内网而言并不关键,特别是ACE本身有极强的安全保护能力
n MSFC上需要源NAT或PBR,以确保由真实服务器发送的返回流量可转发回ACE
n 比较难实现虚拟化ACE与虚拟化防火墙的理想一一对应模式,因为为实现该方式必须把ACE连到VRF上,而当前在Cat6500上基于VRF的PBR还有一些限制
5.2.2.3. 应用负载均衡设计方案比较
根据详细的方案比较,结合XX数据中心网络特点和各应用要求,我们认为当前业务对使用虚拟化ACE的迫切程度远不及防火墙的虚拟化,而相对不需要使用ACE的数据中心业务流量还比较多,因此我们推荐采用单臂模式ACE的方案。在将来业务发展,业务端到端虚拟化要求迫切,并且未来基于VRF的PBR比较完善后,我们还可用比较容易的切换到基于虚拟化ACE的单臂模式。
5.2.3 安全功能的设计
除了服务器负载均衡功能之外,ACE在3.0及以后的版本中还提供强大的应用安全特性,使得单臂模式ACE方案中非处于防火墙保护之内的ACE模块的安全性得到了强有力的保障,这些功能包括:
l 访问控制列表ACL:ACL包括一系列语句,定义网络流量的概况。每个条目允许或拒绝网络流量(入和出)到达条目中规定的网络各部分。除了一个执行单元(允许或禁止)外,每个条目还包括一个基于源地址、目的地址、协议、协议特定参数等标准的过滤器单元。在每个ACL的最后都有一个隐式的拒绝全部的条目,因此在希望允许连接的每个接口上都必须配置一个ACL。否则ACE将拒绝该接口上的全部流量。
l AAA:ACE模块可执行用户身份认证和记账(AAA)服务,为访问ACE的用户提供更高的安全性。AAA服务使得可以使用多个AAA服务器来控制哪些人可以访问ACE,并跟踪访问ACE的每个用户的操作。根据所提供的用户名和口令组合,ACE可使用本地数据库执行本地用户身份认证,或者使用外部AAA服务器来实现远程身份认证和记账。
l 应用协议检查:在数据包通过ACE的时候,某些应用需要对数据包的数据部分进行特别处理。应用协议探测有助于验证协议的行为并识别流经ACE的有害的或恶意的流量。根据通信流量策略的规定,ACE可接受或拒绝数据包,从而确保应用和服务的安全使用。可能需要ACE执行HTTP、FTP、DNS、ICMP和RTSP协议的应用检测,作为将数据包转发到目的服务器前的第一步。对于HTTP,ACE将执行深层数据包检查来监控HTTP协议的状态并根据用户定义的流量策略来允许或拒绝流量通过。HTTP深层数据包检查主要关注HTTP属性,如HTTP报头、URL以及有效负载等。对于FTP,ACE将执行针对FTP会话的FTP明令检查,从而允许您根据ACE限制特定命令。应用检测有助于识别TCP或UDP流中嵌入的IP地址信息的位置。这些检测使ACE可以转换嵌入的IP地址并更新受转换影响的校验和或者其他字段。
l TCP 标准化:TCP标准化是一种第4层特性,包括ACE在数据流传输不同阶段(从最初的连接建立到连接关闭)执行的一系列检查。可以通过配置一个或多个高级TCP连接设置来控制很多分段检查。ACE使用这些TCP连接设置来确定执行哪些检查,并根据检查结果确定是否丢弃一个TCP分段。ACE会丢弃那些显得异常和畸形的分段。这种特性可检查发现非法或可疑(如从服务器发送到客户端的一条SYN,或从客户端发送到服务器的一条SYN/ACK)的分段,并根据配置的参数设置采取恰当的措施。ACE可使用TCP标准化来阻塞某种类型的网络攻击,如插入(insertion)攻击和躲避(evasion)攻击。插入攻击是指设计一种机制,使检查模块接收终端系统
拒绝的数据包。躲避攻击是指设计一种机制,使检查模块拒绝被终端系统接受的数据包。ACE总是自动丢弃坏分段校验和的数据包、坏TCP报头或错误的有效负载长度的数据包、带有可疑的TCP标记 (如 NULL、SYN/FIN或 FIN/URG) 的数据包。
l 网络地址转换:为了给服务器提供安全性,还可以将服务器的专用IP地址映射到一个全局可路由的IP地址。客户端可使用该地址来连接到服务器。在这种情况下,从客户端发送数据到服务器时,ACE将把全局IP地址转换为服务器专用IP地址。相反,当服务器响应客户端的时候,ACE将把本地服务器IP地址转换为一个全局IP地址,以达到安全目的,这个过程称为DNAT。
我们建议在一期建设中由于本项目的数据中心处于内网,来自外部的攻击相对少,可以部分的使用ACE的这些安全特性作为自身保护和对防火墙的功能补充、负担卸载(比如对特定协议的检查),不建议作为主要的安全手段使用。
5.2.4
SSL分流设计
ACE可以实现在网络上协助完成SSL的分流,以减轻后台服务器操作SSL的压力。安全套接层(SSL)是一种应用层协议,为互联网提供加密技术,依赖证书和私钥/公钥交换来实现这一层次的安全性,从而确保安全交易,如为电子商务网站传输信用卡号。通过结合私密性、身份认证以及SSL数据完整性,SSL可在客户端和服务器之间提供安全的数据交易。
ACE模块通过一组特殊的SSL命令组来在客户端和服务器之间执行加密功能。SSL功能包括服务器认证、私钥公钥生成、证书管理以及数据包加密和解密。
ACE支持SSL第3.0版以及传输层安全(TLS)第1.0版。ACE可以理解并接受SSL 2.0版的Client Hello消息(该消息也称为混合2/3 hello消息),从而允许两种版本的客户端同ACE通信。在客户在ClientHello 第2.0版中指明SSL第3.0版时,ACE了解该客户端可以支持SSL 3.0版并返回一条3.0版的Server Hello消息。如果客户端仅支持SSL第2.0版,则ACE不能让网络流量通过。
建议根据不同的应用要求,可以有选择的配置SSL分流(off-loading)功能来为服务器提供数据加密/解密。在SSL Off-loading的情况下,客户端发送 HTTPS流量到ACE VIP,ACE 将SSL 流量转发到板上(on-board)SSL模块进行加密。明文流量将发回到ACE以做出负载均衡决策,然后再转发到真实服务器。从真实服务器发出的返回流量被转发到ACE,ACE再将明文流量发送到SSL模块进行重新加密。然后,加密的流量就发送回ACE,
ACE再将其转发回客户端。从而最终解脱服务器繁重的SSL处理负担。
5.2.5 扩展性设计
XX数据中心网络设计中采用了业务功能模块化和网络拓扑层次化的设计架构,使用了核心、分布和接入层模式,在这种模式下,服务器负载均衡、防火墙、SSL卸载等网络服务在分布层提供。应用承载设计中两个关键部件的性能指标给方案的可扩展性提供了良好支持。
ACE提供业界最高的第4至7层性能,每个模块每秒的吞吐量可达16Gbps,支持的连接数可达345000条。凭借这一最佳性能和250个虚拟分区的支持, ACE可以提供最高的应用和用户群可扩展性。一个Catalyst 6500机箱中最多可以安装4个ACE模块,实现最大的可扩展性。
表 1 ACE性能及容量
特性
最高性能/配置
综合性能
吞吐量
16 Gbps*, 8 Gbps* 和 4 Gbps
每秒通过的数据包数
650万
每秒处理的系统日志数
350,000
内容交换性能
每秒最大连接数
345,000完整的交易速率
同步连接
4 百万
SSL 加速
5K, 10K, 15K* SSL 交易每秒; 默认为1,000
内容交换配置
虚拟服务器
4,096
服务器群
16,000
真实服务器
16,000
VLAN 总量(客户端/服务器)
4000
探测器
ICMP、TCP、UDP、Echo、Finger、DNS、Telnet、FTP、HTTP、HTTPS、
SMTP、POP3、IMAP、RADIUS和Scripted
ACL条目
最多256,000个接入控制单元
虚拟分区
250*,
基本报价包括5 个虚拟分区
VLAN总数 (客户端/服务器)
4000
* 需要购买升级许可
5.2.6 高可用性设计
数据中心的业务和应用都有较高的可用性要求,这就要求网络具有支持业务永续性的冗余能力,这种冗余旨在消除设备或连接故障造成的影响。将这些冗余特性设计在适当的位置,并确保发生故障时数据仍可以从客户端流向服务器很重要。在XX数据中心网络中,从机箱、路由模块、ACE模块、FWSM模块都充分考虑了冗余设计。
5.2.6.1. 路由模块的冗余
Catalyst 6500机柜内有多种硬件特性可用于提供具有弹性的高可用性解决方案。这包括双电源以及双机箱系统。
电源将以冗余模式运行。在这种模式下,如果一个电源出现故障,或者机柜的交流电源出现故障,其余的电源将继续支持机柜的运行。
5.2.6.2. 防火墙模块FWSM的冗余
FWSM支持状态故障切换,这意味着TCP连接和UDP流可从主动防火墙模块复制到备用防火墙模块。发生故障时,备用模块将变成主用模块,继续为已建立的连接转发流量。FWSM故障切换时间大约可在1~3秒。
在前面的设计中我们提到,两个服务机箱采用一主一备的冗余设计,两个机箱的防火墙模块通过一个特定VLAN(Failover VLAN)交换心跳信号和配置同步,从而能够检测出另一设备是否存在任何故障,并选择主用和备用设备。我们还在FWSM之间另外使用一个特定VLAN (Stateful VLAN)来复制防火墙正在转发的流量的状态信息,使得在切换后另一个防火墙上保留所有连接状态信息,可以提供切换前后不中断业务服务。
建议使用单独的冗余物理端口实现Failover VLAN和Stateful VLAN。
5.2.6.3. 应用负载均衡模块ACE的冗余
应用负载均衡设计中,ACE模块的状态冗余就显得尤为重要了。ACE的状态故障切换可以在机箱内得到支持,也可以像XX数据中心网络设计中那样跨不同机柜在对等的ACE模块间实现。
为了支持这种主用/备用配置,可以创建一个FT VLAN接口来传输心跳信号。FT对等设备内定义了心跳信号的频率,例如,每100毫秒和丢失10次心跳信号可视为对等设备丢失。故障切换定时器可由用户配置。
建议使用单独的冗余物理端口实现FT VLAN。
5.2.6.4. 服务器的冗余
服务器的冗余实际是负载均衡服务器群中的多台服务器组成的负载均衡集群实现的,集群中服务器的健康状况主要由ACE进行实时动态监控,可以通过配置运行状况探测器(有时叫作keepalives)来指示ACE检查服务器和服务器群的运行状况。创建探测器后,就可以将它分配给某真实服务器或服务器群。探测器可以是以下类型中的一种:
l TCP
l ICMP
l Telnet
l FTP
l HTTP GET
l HTTP HEAD
根据应用要求,可以调整运行状况探测器的参数,如时间间隔、故障检测(faildetect)、通过探测(passdetect)等,以满足需求。
l 时间间隔:
以秒为单位的探测间隔时间
l 失败探测:
记录真实服务器故障前的续错误数目
l 通过探测: 两次探测到服务器故障之间的时间间隔,单位为秒
负载均衡器定期发出探测信息以确定某服务器的状态,检查服务器响应以及其他可能阻止客户端到达服务器的网络问题。根据服务器的响应,负载均衡器可以使服务器开始运行或停止运行
。根据服务器群中服务器的状态,负载均衡器就可以做出可靠的负载均衡决策。
5.2.6.5. 服务器NIC Teaming(成组)
只有一个NIC接口的服务器可能会存在很多单点故障,如NIC卡、电缆及所连接的交换机。NIC成组是NIC卡供应商开发的一种解决方案,可通过提供特定的驱动器来消除这种单点故障。该方法允许将两块NIC卡连接到两个不同的接入交换机或同一接入交换机上的不同模块端口。如果一个NIC卡出现故障,第二块NIC卡就会接过服务器的IP地址并接替运行而不出现任何中断。NIC成组解决方案有多种类型,包括Active/Standby模式(一主一备)以及Active/Active(双活)模式。
根据单服务器的业务量和Teaming对网络复杂度的影响评估,我们推进的服务器NIC Teaming方式是Active/Standby模式(一主一备),并使用一个IP和共享的MAC地址。
5.2.6.6. 高可用设计下的数据流分析
交换机、防火墙模块、ACE模块,任何一处的故障点都可以单独切换。
比如当前的A机箱内的防火墙故障,另一机箱B的防火墙将接管,应用业务将使用A机箱的VRF、B机箱的防火墙模块、A机箱的ACE完成所有数据流的处理。AB机箱内的数据流交互,通过AB之间的VLAN Trunking完成。
5.2.6.7. 未来高可用性扩展
当前网络智能服务机箱使用主备模式工作,我们可用在未来考虑利用虚拟化技术,使一部分虚拟区以A机箱为主用,一部分虚拟区以B机箱为主用,这样两个机箱将形成Active/Actice的双活模式,形成真正的负载均衡和冗余共存的设计。当然这样的方案也会带来非对称路径处理等诸多复杂设计,我们建议当系统对智能服务的峰值处理量一个机箱内无法承载时,可用升级为这种双活服务机箱模式。
无论主备还是双活,思科都支持通过VSS技术将两个服务机箱虚拟化为一个机箱,以实现更为清晰的智能服务管理和更高性能的网络负载均衡能力。这也是我们可以在未来考虑进一步升级实施的。
第6章
网络安全设计
6.1 网络安全部署思路
6.1.1 网络安全整体架构
目前大多数的安全解决方案从本质上来看是孤立的,没有形成一个完整的安全体系的概念,虽然已经存在很多的安全防护技术,如防火墙、入侵检测系统、防病毒、主机加固等,但是各个厂家鉴于各自的技术优势,往往厚此薄彼。必须从全局体系架构层次进行总体的安全规划和部署。
XX本次信息建设虽然仅包括数据中心、内网楼层以及广域网中心部分的改造和建设,但也必须从全局和架构的高度进行统一的设计。建议采用目前国际最新的“信息保障技术框架(IATF)”安全体系结构,其明确提出需要考虑3个主要的因素:人、操作和技术。本技术方案着重讨论技术因素,人和操作则需要在非技术领域(比如安全规章制度)方面进行解决。
技术因素方面IATF提出了一个通用的框架,将信息系统的信息保障技术层面分为了四个技术框架域:
· 网络和基础设施:网络和基础设施的防护
· 飞地边界:解决边界保护问题
· 局域计算环境:主机的计算环境的保护
· 支撑性基础设施:安全的信息环境所需要的支撑平台
并提出纵深防御的IA原则,即人、技术、操作相结合的多样性、多层叠的保护原则。如下图所示:
主要的一些安全技术和应用在框架中的位置如下图所示:
我们在本次网络建设改造中需要考虑的安全问题就是上图中的“网络和基础设施保护”、“边界保护”两个方面,而“计算机环境(主机)”、“支撑平台”则是在系统主机建设和业务应用建设中需要重点考虑的安全问题。
6.1.2 网络平台建设所必须考虑的安全问题
高速发达的网络平台衍生现代的网络病毒、蠕虫、DDoS攻击和黑客入侵等等攻击手段,如果我们的防护手段依然停留在对计算环境和信息资产的保护,将处于被动。需要从网络底层平台的建设开始,将安全防护的特性内置于其中。因此在SODC架构中,安全是一个智能网络应当对上层业务提供的基本服务之一。
XX网络从平台安全角度的安全设计分为以下三个层次:
设备级的安全:需要保证设备本身的安全,因为设备本身也越来越可能成为攻击的最终目标;
网络级的安全:网络作为信息传输的平台,有第一时间保护信息资源的能力和机会,包括进行用户接入认证、授权和审计以防止非法的接入,进行传输加密以防止信息的泄漏和窥测,进行安全划分和隔离以防止为授权的访问等等;
系统级的主动安全:智能的防御网络必须能够实现所谓“先知先觉”,在潜在威胁演变为安全攻击之前加以措施,包括通过准入控制来使“健康”的机器才能接入网络,通过事前探测即时分流来防止大规模DDoS攻击,进行全局的安全管理等。
XX应在上述三个方面逐步实施。
6.2 网络设备级安全
网络设备自身安全包括设备本身对病毒和蠕虫的防御以及网络协议本身的防范措施。有以下是本项目所涉及的网络设备和协议环境面临的威胁和相应的解决方案:
6.2.1 防蠕虫病毒的等Dos攻击
数据中心虽然没有直接连接Internet,但内部专网中很多计算机并无法保证在整个使用周期内不会接触互联网和各种移动存储介质,仍然会较多的面临大量网络蠕虫病毒的威胁,比如Red Code,SQL Slammer等等,由于它们经常变换特征,防火墙也不能完全对其进行过滤,它们一般发作的机理如下:
· 利用Microdsoft OS或应用的缓冲区溢出的漏洞获得此主机的控制权
· 获得此主机的控制权后,安装病毒软件,病毒软件随机生成大量的IP地址,并向这些IP地址发送大量的IP包。
· 有此安全漏洞的MS OS会受到感染,也随机生成大量IP地址,并向这些IP地址发送大量的IP包。
· 导致阻塞网络带宽,CPU利用率升高等
· 直接对网络设备发出错包,让网络设备CPU占用率升高直至引发协议错误甚至宕机
因此需要在设备一级保证受到攻击时本身的健壮性。此次XX的核心交换机Nexus 7000、智能服务机箱Catalyst 6500均支持硬件化的控制平面流量管制功能,可以自主限制必须由CPU亲自进行处理的信息流速,要求能将包速管制阈值设定在CPU可健康工作的范围内,从根本上解决病毒包对CPU资源占用的问题,同时不影响由数据平面正常的数据交换。特别是Nexus 7000的控制平面保护机制是在板卡一级分布式处理的,具备在大型IDC中对大规模DDoS的防护能力。
另外所有此类的蠕虫和病毒都会利用伪造源IP地址进行泛滥,局域网核心交换机和广域网骨干路由器都应当支持对转发的包进行源地址检查,只有源地址合法的IP包才会被转发,这种技术称为Unicast Reverse Forwarding(uRPF,单播反转路径转发)。该技术如果通过CPU实现,则在千兆以上的网络中将不具备实用性,而本次XX网络中在万兆一级的三层端口支持通过硬件完成的uRPF功能。
6.2.2 防VLAN的脆弱性配置
在数据中心的不同安全域进行防火墙访问控制隔离时,存在多个VLAN,虽然广泛采用端口捆绑、vPC等技术使正常工作中拓扑简化甚至完全避免环路,但由于网络VLAN多且关系复杂,无法在工程上完全杜绝诸如网络故障切换、误操作造成的临时环路,因此有必要运行生成树协议作为二层网络中增加稳定性的措施。
但是,当前有许多软件都具有STP 功能,恶意用户在它的PC上安装STP软件与一个Switch相连,引起STP重新计算,它有可能成为STP Root, 因此所有流量都会流向恶意软件主机, 恶意用户可做包分析。局域网交换机应具有Root guard(根桥监控)功能,可以有效防止其它Switch成为STP Root。本项目我们在所有允许二层生成树协议的设备上,特别是接入层中都将启动Root Guard特性,另外Nexus5000/2000还支持BPDU filters, Bridge Assurance等生成树特性以保证生成树的安全和稳定。
还有一些恶意用户编制特定的STP软件向各个Vlan加入,会引起大量的STP的重新计算,引起网络抖动,CPU占用升高。本期所有接入层交换机的所有端口都将设置BPDU Guard功能,一旦从某端口接收到恶意用户发来的STP BPDU,则禁止此端口。
(三)防止ARP表的攻击的有效手段
本项目大量使用了三层交换机,在发送数据前其工作方式同路由器一样先查找ARP,找到目的端的MAC地址,再把信息发往目的。很多病毒可以向三层交换机发一个冒充的ARP,将目的端的IP地址和恶意用户主机的MAC对应,因此发往目的端的包就会发往恶意用户,以此实现包窃听。
在Host上配置静态ARP是一种防止方式,但是有管理负担加重,维护困难,并当通信双方经常更换时,几乎不能及时更新。
本期所使用的所有三层交换机都支持动态ARP Inspection功能,可动态识别DHCP,记忆MAC地址和IP地址的正确对应关系,有效防止ARP的欺骗。实际配置中,主要配置对Server和网络设备实施的ARP欺骗,也可静态人为设定,由于数量不多,管理也较简单。
6.2.3 防止DHCP相关攻击
本项目中的楼层网段会采用DHCP
Server服务器提供用户端地址,但是却面临着几种与DHCP服务相关的攻击方式,它们是:
l DHCP Server 冒用:当某一个恶意用户再同一网段内也放一个DHCP 服务器时,PC很容易得到这个DHCP server的分配的IP地址而导致不能上网。
l 恶意客户端发起大量DHCP请求的DDos 攻击:恶意客户端发起大量DHCP请求的DDos 攻击,则会使DHCP Server性能耗尽、CPU利用率升高。
l 恶意客户端伪造大量的MAC地址恶意耗尽IP地址池
应采用如下技术应对以上常见攻击:
· 防DHCP Server 冒用:此次新采购的用户端接入交换机应当支持DHCP Snooping VACL, 只允许指定DHCP Server的服务通过,其它的DHCP Server的服务不能通过Switch。
· 防止恶意客户端发起大量DHCP请求的DDos 攻击:此次新采购的用户端接入交换机应当支持对DHCP请求作流量限速,防止恶意客户端发起大量DHCP请求的DDos 攻击,防止DHCP Server的CPU利用率升高。
· 恶意客户端伪造大量的MAC地址恶意耗尽IP地址池:此次新采购的用户端接入交换机应当支持DHCP option 82 字段插入,可以截断客户端DHCP的请求,插入交换机的标识、接口的标识等发送给DHCP Server;另外DHCP服务软件应支持针对此标识来的请求进行限量的IP地址分配,或者其它附加的安全分配策略和条件。
6.3
网络级安全
网络级安全是网络基础设施在提供连通性服务的基础上所增值的安全服务,在网络平台上直接实现这些安全功能比采用独立的物理主机实现具有更为强的灵活性、更好的性能和更方便的管理。在本次数据中心的设计范围内主要是访问控制和隔离(防火墙技术)。
从XX全网看,集团网络、各地机构广域网、互联网、内部楼层、内部数据中心等都是具备明显不同安全要求的网络,按飞地边界部署规则,都需要有防火墙进行隔离。本文档仅讨论数据中心部分内部的防火墙安全控制设计。
6.3.1 安全域的划分
数据中心安全域的划分需要建立在对数据中心应用业务的分析基础之上,因而与前述的虚拟服务区的划分原则一致。实际上按SODC的虚拟化设计原则,每一个虚拟服务区应当对应唯一的虚拟防火墙,也即对应唯一的一个安全域。具体原则如下:
l 同一业务一定要在一个安全域内
l 有必要进行安全审计和访问控制的区域必须使用安全域划分
l 需要进行虚拟机迁移的虚拟主机要在一个安全域中
l 划分不宜过细,安全等级一致的业务可以在安全域上进行归并,建议一期不超过5个安全域
一般可以划分为:OA区,应用服务区,数据库区,开发测试区等。
6.3.2 防火墙部署设计
各个安全域的流量既需要互访、又必须经过严格的访问控制和隔离,如果按照传统的网络设计,需要在每个网络应用和交换平台之间的边缘部署防火墙设备来进行安全保护,这样需要大量的防火墙,性能也受限于外部连接接口的带宽,还增加了网络管理的复杂度,未来也难以扩展。因此我们应当使用内置于交换机的高性能防火墙模块,可以不考虑复杂的连线而方便的进行安全域划分,容易扩展和管理,也提高了整体性能。
如果每个安全域有自己的防火墙,那么每一个安全域就只用考虑自己的一套出入策略即可,
安全域复杂的相互关系变成了每个安全域各自的一出一进的关系,这样整个防火墙的策略就变得模块化、清晰化和简单化了。我们在诊断策略的问题时,只要到相关的安全域去看其专用的防火墙所使用的策略,就容易找到问题所在。我们在本次防火墙设计中将充分使用虚拟防火墙技术。
这里的虚拟防火墙功能是指物理的防火墙可以被虚拟的划分为多个独立的防火墙。每个虚拟防火墙有完全独立的配置界面、策略执行、策略显示等等,所有操作就象在一个单独的防火墙那样。而且虚拟防火墙还应当具有独立的可由管理员分配的资源,比如连接数、内存数、策略数、带宽等等,防止一个虚拟防火墙由于病毒或其它意外而过多占用资源。仅仅用VLAN一类的技术划分防火墙是无法起到策略独立性和资源独立性的目的的,不属于这里所指的虚拟防火墙。
虚拟防火墙还应当配合虚拟三层交换机来使用。每一个安全域可能内部存在多个IP子网,它们之间需要有三层交换机进行路由。但不同安全域之间这样的路由不应当被混同在一个路由表中,而应当每个安全域有自己的路由表,可以配置自己的静态和动态路由协议,就好像有自己独立使用的一个路由器一样。不同安全域相互之间仅通过虚拟防火墙互相连接。因此各个安全域的互连逻辑结构如下图所示:
最终应当达到虚拟化数据交换中心的使用效果。即交换机的任何物理端口或VLAN端口都能够充当防火墙端口,同时每个安全域有自己独立虚拟路由器,自己独立的路由表和独立的动态路由协议。每个安全域对应有一个自己专用的虚拟防火墙,每个虚拟防火墙拥有独立的管理员权限定义安全策略和使用资源。不同安全域的管理员只负责本区域虚拟防火墙的策略控制管理,而不用关心其它虚拟防火墙的配置工作,避免了单一区域安全策略配置错误而对其它区域可能造成的影响,从根本上简化大型数据中心管理维护的难度。
对防火墙模块的物理和逻辑的部署请参见前面“智能服务机箱设计”一节。
6.3.3 防火墙策略设计
不同安全域之间的访问控制策略由于虚拟化设计而只需考虑各个安全域内出方向策略和入方向策略即可。建议初始策略依据如下原则设定,然后根据业务需求不断调整:
l 出方向上不进行策略限制,全部打开
l 入方向上按“最小授权原则”打开必要的服务
l 允许发自内部地址的双方向的ICMP,但对ICMP进行应用检查(Inspect)
l 允许发自内部地址的Trace Route,便于网络诊断
l 关闭双方向的TCP Seq Randomization,在数据中心内的防火墙可以去除该功能以提高转发效率
l 减少或者不进行NAT,保证数据中心内的地址透明性,便于ACE提供服务
l 关闭nat-control(此为默认),关闭xlate记录,以保证并发连接数
l 对每个虚拟防火墙的资源进行最大限定:总连接数,策略数,吞吐量
l 基于每个虚拟防火墙设定最大未完成连接数(Embryonic Connection),将来升级到定义每客户端的最大未完成连接数
6.3.4 防火墙性能和扩展性设计
本期项目建议采用的防火墙模块是具有5.5Gbps吞吐量、100万并发连接数、每秒10万新建连接数能力的高端防火墙系统。如下表所示:
表
FWSM性能和容量
特性
最高性能/配置
综合性能
5.5 Gbps
3 M pps
100万条同步连接
每秒100,000条HTTP/HTTPS连接
256,000 当前 NAT 和 PAT转换
全局配置
VLAN接口
每个服务模块1000个
路由模式下每个虚拟防火墙256个VLAN
透明模式下每个虚拟防火墙8对VLAN对
接入控制列表
在单一虚拟防火墙模式下最多为80,000个ACLs
虚拟防火墙
20、50、100或250个 虚拟防火墙许可证
虽然在双活模式下,本项目的防火墙系统最大可以提供高达11Gbps的吞吐量,但作为未来的数据中心防火墙系统,我们认为还应当具备完全线性的吞吐量能力。幸运的是在本次提供的最新一版防火墙模块中,我将提供高达32Gbps的单模块吞吐能力,甚至以后可以扩展到300Gbps以上。这需要在防火墙模块上实现思科的最新技术:SUP Acceleration(引擎加速)。
在数据中心大数据量交互中,最占据防火墙处理开销的不是黑客攻击、越权访问等这些被拒绝的流,而是存储、备份、文件传输、虚拟机映像加载、内存同步等等大带宽消耗的正常应用的可信任流,它们的特点是在持续稳定的TCP连接或UDP会话中以最大的可传送能力(Best Effort)进行数据传送,往往可以侵占巨大的带宽,传统的防火墙对这类流量都会逐包进行检查处理,将导致防火墙内部处理的拥塞。思科的新一代防火墙模块可以实现“借用”交换机的资源提高防火墙模块自身的吞吐性能。实际上防火墙可以对一个流的前几个包进行处理,当得到这个流是可以通过的信任流的结论后,将这个流的特征提取出来送给交换机,交换机就用这个特征对流的后续包进行识别和处理,相当于这个流的后续部分交给交换机来完成了,这样交换机的资源和防火墙的资源实现真正的融合,大大提高的安全访问控制的处理速度,以前单个防火墙模块可以实现实测的5.5Gbps的吞吐量,而在使用资源整合技术之后,这个数值实测已经达到32Gbps,而且可以软件升级到300Gbps以上的防火墙模块。这正是面向服务的数据中心对资源整合化的典型技术实现,也为客户带来的资源融合的益处。
我们在全球多个大型数据中心的实际使用环境中通过调查发现,除去这些“可信任流”,其余流量使用防火墙本身的5.5Gbps处理能力都是绰绰有余的,因此在本项目中一期工程中即使不采用双活的智能
服务机箱,也足以保证防火墙环节的无瓶颈。未来还可以通过2个防火墙模块的双活,甚至使用虚拟ACE实现4个防火墙模块的双向负载均衡。
6.4
网络的智能主动防御
传统的不停的打补丁和进行特征码升级的被动防御手段已经无法适应安全防御的要求,必须由网络主动的智能的感知网络中的行为和事件,在发生严重后果之前及时通知安全网络管理人员,甚至直接联动相关的安全设备,进行提早措施,才能有效减缓危害。要实现这种智能的主动防御系统,需要网络中进行如下部署:
· 对桌面用户的接入进行感知和相应措施
· 对桌面用户的行为进行分析和感知
· 对全网安全事件、流量和拓扑进行智能的分析、关联和感知
· 对各种信息进行综合分析然后进行准确的报告
· 在报告的同时进行网络的联动以提早抑制威胁
以上整个过程需要多个产品进行部署才能实现。以下对这些产品的部署进行简述。
6.4.1 网络准入控制
网络准入控制技术——Network Access Control(NAC),就是一种由网络智能对终端进行感知,而判断其威胁性,从而减少由终端发起的攻击的一种技术。NAC类似于前面提到的身份识别安全接入控制技术,只不过它对主机、网络设备等接入的判别标准不仅仅是基于用户身份的,而是基于该设备的“网络健康状态”。NAC允许各机构实施主机补救策略,将不符合安全策略要求及可疑的系统放置到隔离环境中(比如一个特定的专用于软件升级的VLAN),限制或禁止其访问生产网络,等威胁消除后,再回到生产网络。通过将端点安全状态信息与网络准入控制的执行标准结合在一起, NAC使各机构能够大幅度提高其计算基础设施的安全性。
在XX实施的准入控制,需要能够实现以下要求:
· 一体化的准入控制:不仅仅是有线端的准入控制,而且要实现包括无线、VPN接入在内的准入控制,而且应当是统一的一个系统下的准入控制,这就需要以太网交换机、无线AP设备、无线控制器、VPN集中器都可以支持统一的准入控制;
· 支持多种准入控制形式:包括能够支持基于Infrastructure的准入控制,比如对于有线局域网、无线局域网可基于实现IEEE 802.1x和动态VLAN的准入控制,对于路由器、防火墙、VPN集中器等等可实施基于过滤机制的准入控制,也可以支持基于网络专用设备的准入控制,比如对于网络交换机、路由器是由不同厂商品牌设备构成的异构网络也可以实施基于专用在线设备的准入控制;
· 与身份标识相结合:准入控制机制应当与身份标识是一体化的,不同身份标识的用户可以有相应的准入控制策略,即对身份的识别和对健康的检查可以进行联系;
· 独立对客户机健康状态进行评估:能够结合其它病毒厂商软件进行安全状态检查,更可以独立对客户端行为进行检查,包括操作系统补丁、病毒软件版本等,还应当包括检查注册表可疑记录、非法修改等等,能够通过对客户机状态进行深度判断,而基本上脱离复杂的第三方厂商病毒软件的部署而独立对健康状态进行准确评估。
· 提供自动修复:准入控制系统应包括提供在线的自动修复能力,包括各种策略的软件分发和链接推送等。
· 能够发现和自动识别打印机、IP电话等非常规NAC客户端
本期将主要以数据中心的建设为主,建议XX在以后的楼层接入的完善化建设中考虑对桌面的准入控制解决方案。
6.4.2 桌面安全管理
准入控制是一种网络对接入主机的智能判断,但一般只能在接入的瞬间进行检查和动作,用户在接入后进行的操作、收发的信息,准入控制系统不再干预。而网络各种病毒、蠕虫和黑客软件的泛滥与每个客户机本身的上网行为是分不开的。一个大型企业网的管理员无法真正控制用户端的行为,是网络变得脆弱和事故频发的主要祸首,也是管理员最头痛的问题。
XX随着将来IT业务的深化发展,需要这样的桌面安全管理软件——基于行为特征来保护终端的技术。客户端软件是基于行为而不是基于特征码标记的,即不管这个病毒是不是我识别库里的,只要其行为危害了系统,就可以被阻止,客户端软件看行为进行专家级的分析,这样可以减少频繁的对客户端软件的升级,更重要的是能够防止终端免受所谓“零日攻击”,即那些还未被人们所了解的病毒、蠕虫、间谍软件、恶意代码以及最新的变种的危害,另外还能基于应用程序、行为实施各种安全策略,对用户本人进行的有意或无意的系统危害进行管理和控制。具体应当有如下功能:
· 识别恶意或无意的不安全行为:对各种威胁行为,比如不支持的注册表修改、不正常的内存访问、收到对本机端口不正常的扫描、对邮件系统不正常的后台调用等等,无论是病毒还是用户有意或无意造成的,都可以即时提示用户进行阻止,也可以不提示用户,而是作为一条Log信息报告给后台的安全智能网管。
· 自动统计PC上安装了哪些应用程序:能统计客户机器上都安装了哪些应用程序,以及安装的版本。如是否安装了BT等软件。然后向后台安全智能网管报告。
· 调查应用程序的运行情况:能统计哪些应用程序在运行,并生成相应的报表报告给后台智能网管。
· 禁止安装和运行管理员指定的应用程序:能够禁止客户机安装和运行不符合公司策略的应用程序,比如BT,钓鱼软件等。
· 保护敏感数据,不允许复制、拷贝:被保护的文件可以打开阅读,但是不能复制,无论是复制文件或文件夹,都不允许,也不能从文件中拷贝、粘贴内容出来,所以是非常好的防止机密信息泄漏的方法。
· 禁用USB等移动设备:USB、光驱等各种可移动设备,常常是引入病毒、风险的入口。客户端管理软件应当可以设定不允许特定的客户机上的这些设备,或者只能看设备上有什么内容,但是不允许读。只有当管理员授权时,才能使用和访问。
· 统计并能够控制应用程序对网络使用:可以统计应用程序对网络的使用情况,提供对应用程序使用网络的控制,比如可以让制订应用的IP包打上QoS标记,禁止访问指定的网段,禁止邮件附带机密文件等等。
· 能够和准入控制相结合:能够和准入控制无缝结合,比如准入控制对终端健康的识别包括了是否安装了客户端安全管理软件,是否制订了相应安全级别的策略;反过来,客户端安全管理软件也可以根据准入控制的结果(是隔离还是已被允许进入网络)来提供不同的安全保护策略。
· 中央集中控管:客户端管理软件由中心进行软件分发,由中心网管进行统一策略设置、维护和升级,集中控管, 维护简单。
· 后台报警、报表:所有以上功能都即时跳出窗口,让用户了解安全威胁,询问用户是否阻止,也可以让用户在使用时完全无知,而把详细的使用情况报表、报警等通过后台传送给集中控管的智能安全网管控制台,使管理员对整个用户网络使用情况一目了然,而提早采取措施。
以上的功能由一个集中控管的服务器端管理软件和分布在各个用户主机上的客户端软件构成。通过中心策略设置,将客户端软件分发到各个客户端主机,将工作模式设为后台告警和报表模式,减少对前端用户正常工作的干扰,而让管理员了解所有计算机的安全运作情况,再根据这些信息确定安全预防措施
。
建议在以后逐步实施的楼层网络优化和改造项目中再实施类似对客户端桌面的管理和控制。
6.4.3 智能的监控、分析和威胁响应系统
XX已经部署、而且还将部署大量的各种安全设备,它们的使用都需要人来去参与,这形成了巨大的安全管理挑战。当一个常见的蠕虫早期发生时,相关的网络设备、防火墙、IDS/IPS都会有异常记录产生,而这些都会淹没数以万计的日志和告警之中,管理员很难发现,往往等待其爆发、形成损失再去调查。而即使我们能够把爆发过程所有信息都拿到,也难以从如此多的设备、如此多的记录中分析其爆发的源头。
XX网管中心需要一个智能的安全管理系统,它应当象一个精通所有网络安全设施的专家,由他来帮助我们进行早期预警、源头跟踪、措施建议等等。安全监控、分析和威胁响应系统”(Monitor, Analysis and Response System,MARS)具体应当包括这样的功能:
· 监控安全设备:MARS系统能够监控所有安全设备形成了日志、记录和告警,进行收集;
· 监控网络拓扑形态:MARS系统能够了解整个网络拓扑、设备类型和路由表、地址表等等信息;
· 监控网络流量:MARS系统能够监控网络中的各种流量,比如某个特定TCP/UDP端口号的流量变化,能够采集设备的Netflow 信息,进行统计、形成日常基线,从而能够识别异常流量;
· 监控网络设备:MARS系统能够监控各种厂商的网络设备的记录,包括路由器、交换机、VPN设备、NAT等等;
· 统一进行分析功能:MARS把以上的所有监控信息统一进行分析,特别是和网络的拓扑和异常流量相关联,从而将各种看似分离的事件相关联,把各种重复的、错误的报告删除,最后把浩如烟海的问题报告浓缩成少量的安全事故报告,供管理员参考。往往数十万个告警最后仅剩下十几个高中低不同优先级的事故报告。
· 形象的呈现:最后的事故报告可以向管理员清晰的描述攻击的源、路径、目标,攻击次数等等,并且在网络拓扑图中将上述信息标识处理,供管理员参考。
· 智能专家建议:根据发生的安全事故,MARS可以向管理员进行智能建议,比如对拓扑和路径智能分析后告诉管理员应在何处最佳位置进行过滤,过滤应采用的访问控制列表的具体命令等等。
· 远程修复:通常MARS可以自动形成多个措施建议,供管理员选择,一旦管理员同意某个措施,这个措施,比如写一个访问控制列表或关闭一个端口,就会自动被发向目标设备,自动完成修复。
· 兼容各厂商设备:MARS应当可以对各个主流网络设备厂商、安全设备厂商的设备都能予以支持,对于少量非主流的厂商设备MARS可以经过简单的定制予以支持。
MARS必须有别于上一代的安全信息管理系统(SIMS),需要增强如下功能:
· 信息收集和关联的方式:MARS监控的内容不仅仅是安全设备的记录,还包括网络的拓扑和流量信息,把这些与安全事件相关联所进行的判断更准确;
· 信息报告的方式:MARS可以显示整个网络的拓扑,能够把攻击形象的标识在拓扑图上,管理员可以清晰的掌握网络安全威胁波及的源头和范围,从而主动的进行防御;
· 修复的智能化和自动化:MARS可以直接建议安全措施,甚至将安全措施具体表现在命令一级,管理员只需要按一个按钮,就直接进行远程设置和修复。
下图是直观的攻击拓扑显示。
下图是对攻击源所在位置的直观显示:
下图是MARS对抑制该攻击的建议,只需点击Push,就可以对攻击源所在的交换机进行设置,帮助你抑制正在发生的攻击。
建议将来在XX考虑全局网络运营管理时应部署MARS系统,而且在部署MARS时应同时部署与MARS兼容的网络状态监控设施,这些设施包括IDS/IPS、防火墙、网络设备、流量监控设备等。建议XX在未来部署网络状态监控设施时应当考虑如下部署原则,以保证MARS系统作用的充分实现:
· IDS/IPS要求:作为MARS信息的主要来源,XX的楼层局域网应部署硬件IDS以监控核心局域网,一二级网络之间应部署硬件IDS以监控国家级主干和省级的接入,IDS应当为内置或至少1G连接带宽的外部IDS;广域网的接入路由器应支持内置或外部IPS,但要保证一定性能。
· 防火墙要求:按前面安全域隔离方案部署防火墙,防火墙应有完整Log记录和NAT记录,能够和MARS兼容。(目前推进的数据中心防火墙方案满足此要求)
· 网络设备要求:网络主干设备应当具有硬件化的流量华能芯片或模块,能够支持Netflow硬件化采集,并能够在万兆核心交换板卡上提供1:1的取样(Sampling)能力。网络设备还应当对主要的安全事件(如ACL过滤、NAT等)提供Log和审计。(目前Nexus 7000完全满足此要求)
· 兼容性要求:主要网络设备(IDS、防火墙、中高档路由器和交换机等)应当能与MARS系统兼容,其监控信息报告无须定制即可被MARS系统直接使用,也可以接受MARS系统的控制以实现安全响应。对于其它少量不兼容设备,MARS系统应可以支持通过定制化方式监控和管理。(目前Cisco设备、主流国外厂商设备可以满足此要求,国内厂商设备需要定制)
6.4.4 分布式威胁抑制系统
XX云计算平台将通过广域网连接大量托管服务器,对于这样大规模多点分布式的网络,就更难于在中心总部来控制远程各点的安全接入,而广域网对于蠕虫、病毒等威胁又更敏感,只有一种病毒爆发,广域网线路就可轻易被塞满,各类业务都将无法正常传输。必须考虑在分布的各个广域网点都进行有力的遏制,即实现“分布式威胁抑制”。
在各地孤立的部署防火墙和IDS/IPS是一种解决办法,但会有管理、成本和性能功能相互矛盾的问题,即要有效的抑制,就需要在各地有较完善的IDS/IPS和防火墙系统,但管理难度、成本将非常高。
XX可以考虑形成以MARS系统为管理核心、各个网络设备内置安全防御系统的分布式威胁抑制系统。 其主要实现特征如下:
· 管理:在中心使用MARS系统,可以管到所有分布在地方节点的安全设施,而且MARS的拓扑发现、报警收集、事件分析报告、直观的威胁路径图形、远程自动修补等等的功能,可以保证分散的安全设施的有效管理;
· 成本:MARS可以配合内置有IPS、防火墙功能的路由器,可以节省单独购买IPS、防火墙系统的经费;
· 性能和功能:这是MARS分布式攻击抑制解决方案的核心。网络设备内置有IPS、防火墙等功能,如果通过软件由CPU来完成,其性能和功能肯定不具备实用性,如果内置专门的IDS/IPS硬件模块,则对大规模的分散节点将形成极高的成本投入,而MARS是这样解决这个矛盾的:
o 通过路由器软件完成的IPS会有性能和功能问题的主要原因是IPS是基于状态的特征码识别系统,需要在高速数据流中提取特定识别信息,与一个巨大的病毒特征码数据库进行匹配。如果由CPU去完成,其性能可想而知。因此内置的软件IPS功能只能开启很少的特征识别码。实际上一个企业在一段时期内只会被一种或少数病毒所困扰,不可能在一个网络中同时发生着历史跨度极大的数百种病毒,因此路由器对每个数据包逐一去匹配一个完整的病毒特征数据库是没有必要的。放在省级节点的MARS可以具有这样的功能,就是它从本地网络中心的硬件IDS/IPS中探知当前正在发作的几种病毒,然后将其特征码收集后推送到各下级单位节点的路由器上,这些路由器的IPS仅仅装载这几种特征码,然后进行高效率的识别匹配,这种按需进行匹配的IPS可以成功的解决低端路由器病毒过滤的性能问题,而且还自动完成了特征码的升级和维护。
分布式威胁抑制实现机制图示如下:
MARS系统为中心的分布式威胁抑制系统要求:
· 中心总部配置MARS系统
· 中心总部配置高性能的硬件IDS/IPS模块或单元设备
· 分布在各个下属单位的中低端路由器支持内置IDS/IPS功能(软件硬件皆可),并与MARS特征码推送功能兼容
建议在未来实现XX全国网络规划改造时,可以考虑实施这种经济简单同时又能最大限度的保证广域网线路稳定可靠的远程分布式威胁抑制解决方案。
第7章
服务质量保证设计
7.1
服务质量保证设计分类
XX本次网络的服务质量保证(QoS)设计主要包括两个方面:
l 数据中心服务质量设计:由于采用Data Center Ethernet技术,因此主要是DCE以太网QoS设计;
l 传统局域网广域网服务质量设计:这一部分业务类型复杂,包括业务数据、IP电话、视频会议等等,加上传统局域网和广域网技术都有自身机制和带宽资源的制约,因此是QoS设计的重点,这部分将主要是IP QoS设计。
7.2
数据中心服务质量设计
本次数据中心采用Data Center Ethernet(DCE)技术,DCE的设计目标之一就是为未来大型数据中心的业务提供传输保障。我们知道衡量QoS质量的四个要素是:带宽,延迟,延迟抖动和丢弃率。在资源整合后的面向服务的数据中心中,对带宽、延迟和丢弃率的要求是非常苛刻的,因此要达到新一代数据中心的设计目标,必须使DCE能够满足对带宽、延迟和抖动的服务质量要求。
7.2.1 带宽及设备吞吐量设计
保证在资源整合后的网络传输带宽和网络设备吞吐能力,必须实现以下DCE设计:
7.2.1.1. 设备吞吐能力
选择的设备必须能够提供足够的交换容量,Nexus 7000具备4Tbps的交换吞吐能力,每插槽230Gbps(可扩展500Gbps);在接入层设备选择上采用接近1.2Tbps交换能力的Nexus 5000,并使用交换延展设备Nexus 2000将这一交换能力线性延展到每个服务器机柜。
7.2.1.2. 带宽设计
首先要在数据中心的拓扑设计中规划好带宽。在本次设计中接入层的每列机柜基本上保证每服务器接入网络的线速,这是依靠每台柜顶交换机(Nexus 2000)上连时的4个万兆链路捆绑后所提供的带宽保证,另外Nexus 5000的1.2Tbps交换能力也保证了所有万兆汇聚后的无瓶颈处理。
数据中心当前最大规模的带宽占用还是在服务器之间的内存同步、并行计算、数据备份和融合SAN之后的存储访问,如果能够将未来支持FCoE的存储机柜设计在Nexus 5000接入,其它万兆网卡的高性能服务器直接在Nexus 5000所在机柜接入,并保证服务器机柜分配得当的条件下,以上大量资源耗费的处理都可以在接入层的同一对Nexus 5000内完成,因此基本可以保证带宽的线性处理。
而接入层到数据中心汇聚层(Nexus 7000的VDC)的连接中是有一定过载,这些过载也只针对跨越两对Nexus 5000即两个列(也可称为POD)之间的流量,当前每对Nexus 5000到7000之间采用4个万兆,在万兆端口数量不紧张的情况下还可以扩容并保证跨机箱的vPC技术实现充分负载均衡的端口捆绑。而考虑到当前服务器数量远没有达到完全过载数量,而且在适当安排服务器后两列之间的流量基本上非常少,大部分带宽消耗型应用将在列内完成,因此当前的过载比是完全满足当前和至少今后5年内的数据处理量要求的。
数据中心服务机箱(Catalyst 6500)和数据中心汇聚(Nexus 7000 VDC)之间当前的设计带宽是每机箱双万兆上连(40Gbps全双工吞吐量),这个数值已经超过当前每个机箱内的单防火墙模块在引擎加速特性下的吞吐能力(32Gbps)和单ACE模块的最大处理性能(16Gbps),因此也没有连接瓶颈。在以后智能服务扩容时,互连的带宽还可以继续扩容,通过vPC和VSS技术保证跨机箱捆绑的充分负载均衡。
从数据中心汇聚到全网核心(Nexus 7000的VDC之间)则可以通过灵活的万兆线路跳接方便的扩容互连带宽,根据整个股份公司对数据中心访问量的评估,当前的互连方式(全双工超过80Gbps)也是完全满足至少5年的业务发展需求的。
7.2.1.3. DCE带宽管理:
在以上的理论分析中,带宽设计已经完全满足本次设计的需要,但是我们可以看到即使最完美的设计也不可能保证网络中处处线性、没有过载,这是不必要也不经济的。在出现过载的位置,我们可以通过技术手段使得最需要带宽的服务能够保证优先获得资源,这也是服务质量保证设计的重点。
在本次推荐的DCE网络技术中已经完全支持IEEE最新的带宽管理技术802.1Qaz ETS(Enhanced Transmission Selection),该技术可以保证在过载情况下优先保证如高性能计算网、存储网流量的带宽,而一般数据业务可以灵活、高效的使用剩余有效带宽,如下图所示11G对10G过载情况下的QoS优化带宽分配:
7.2.2
低延迟设计
DCE的资源汇聚使得存储业务和高性能计算业务都将在一个交换平台上传送,DCE的一个重要要求就是保证这些网络原来的低延迟、低抖动能力一样可以在以太网上获得,这主要依靠设备的低延迟转发特性和在拥塞情况下高级的队列调度来实现。
在本期所推荐采用的Nexus系列交换机最大特点就是使用了Cisco在MDS系列存储交换机上实现的SAN网络低延迟技术和专利,使以太网交换机获得了极低的转发延迟,三层端口对端口的转发延迟可在10~20us,而二层的端口见转发延迟可在3个us以下。充分保证
远程存储读写、远程内存访问的流畅性。
与带宽设计时一样,网络不可能在任何位置都通过充裕的资源,在适当的进行带宽分配和设计后,在许多关键的位置虽然存在过载,但仍不会带来资源的紧张。但仍可能出现突发和不可预测的资源分配不够的问题,这时就需要采用高级的队列管理和调度,对延迟不敏感的业务主动出让一些资源,以保证对延迟极为敏感的业务服务质量不受影响。在以太网上协调资源实现类似流量控制的很早就有,比如最常见的端口暂停帧机制(IEEE 802.3 Annex 31B),当有拥塞发生时通过互连端口信息的传递,让端口流量发送暂缓,以保证自己有足够的资源处理关键业务。而这种传统的控制方式将导致一个物理端口内的所有业务的暂停,导致不可预料的延迟。
本次我们采用的DCE网络支持IEEE最新的Priority Flow Control (IEEE 802.1Qbb)技术,如下图所示,可以对多达8种不同业务给与完全不同的流量区别,从而保证迫切需要资源的存储、访存类业务流的低延迟优先性。
8类业务可以常规QoS的802.1Q优先标识和IP Precedence优先标识进行统一定义。
7.2.3 无丢弃设计
资源缺乏会导致系统对业务进行丢弃,而存储业务、高性能计算业务等是对丢弃极为敏感的,由于业务机制对延迟和成功率的苛刻要求,即使少量的丢弃也会对业务效率产生极为严重的影响。DCE有
“无丢弃以太网”的别称,就是在许多方面改善了传统以太网易于丢弃的简单流控行为。主要表现在以下方面:
l Switch Fabric VoQ:这是SAN交换机的交换矩阵以及运营商核心设备所广泛采用的矩阵队列调度方式,现在该技术广泛使用在DCE的各级设备,有效的避免在设备交换处理时的头端堵塞现象,保证高优先级流量的无丢弃。
l 硬件化的Credit 机制:这也是传统SAN交换机在硬件上保证的传输无丢弃技术,它通过收发双方能有一个互相沟通收发能力的计数器相互协商对方的发送和接收能力,以一种高效沟通的方式保证在底层传输上的无丢弃。现在该技术以在DCE的各级交换机上采用,保证收发以太网帧可以象过去收发存储FC帧一样做到无丢弃。
l Per Virtual Lane (VL) Credit:上面的技术是物理端口级别的,在DCE中还将这种硬件Credit技术用在端口内的Virtual Lane级别,这意味着在同一收发双方的物理口内,可以实现不同业务采用不同Credit参数,实现不同的流控要求,比如传统数据不进行这种机制以节约资源,而FCoE帧则必须使用该机制,而它们都将在一对收发物理接口内共存。
l BCN/QCN (IEEE 802.1Qau):这是一种后向拥塞控制机制,它最大的特点是可以在网络中检测出拥塞,然后发信令到源头,来降低过载的流量,使拥塞得以缓解,并保证优先业务无丢包。该技术曾用于ATM等精细流量管理的网络中。如下图所示。
第8章
网络管理和业务调度自动化
自动化是SODC架构中上层自动优化的实现服务调用必须条件。在高度整合化和虚拟化的基础上,服务的部署完全不需要物理上的动作,资源在虚拟化平台上可以与物理设施无关的进行分配和整合,这样我们只需要将一定的业务策略输入给智能网络的策略服务器,一切的工作都可以按系统自身最优化的方式进行计算、评估、决策和调配实现。
作为SODC一种理想的管理和业务调度方式,完全的自动化是需要坚实的DCE建设基础的。我们可以在新型DCE网络建设并稳定运行后逐步实施一些自动化措施。
作为SODC的提出和倡导厂商,思科公司已经商用化一些管理自动化和业务自动化解决方案,下面简单介绍,以作为未来实施的参考。
8.1
MARS安全管理自动化
思科的网络监测、分析和响应系统(Monitoring, Analysis & Response System,MARS)能够感知网络中发生的各种安全事件,包括网络的拓扑、设备的配置、地址转换、各种安全设备的记录、流量状况和分布……等等,然后加以智能分析、关联和过滤,最终发现不同安全等级的安全威胁,并把他们形象的表示在管理员的拓扑图上,最重要的是可以即时根据安全事故的具体情况产生相应的补救策略,自动完成网络相关设备的配置,实现真正自动、自主的主动安全防御。因此MARS是一种自动调用底层资源实现安全服务的机制。这在前面的安全设计中已有介绍。
8.2
VFrame业务部署自动化
思科的VFrame系统,可以根据输入的业务逻辑,自动按最优化资源来配置智能网络中的虚拟网、虚拟防火墙、服务器虚拟化软件、虚拟存储、虚拟负载均衡等设施,自动完成包括安全、存储、计算等在内的数据中心业务部署规划,最大限度的减少管理复杂度,提高了物理资源使用效率,而管理漏洞和差错则降为最低。
以上两种自动化服务部署技术可以在XX的数据中心基础设施整合和虚拟化部署到一定程度后逐步进行实施。
第9章
服务器(UCS)组件及高可用性
9.1
思科统一计算系统(UCS)简介
思科统一计算系统是下一代数据中心平台,在一个紧密结合的系统中整合了计算、网络、存储接入与虚拟化功能,旨在降低总体拥有成本(TCO),同时提高业务灵活性。该系统包含一个低延时无丢包万兆以太网统一网络阵列,以及多台企业级x86 架构服务器。它是一个集成的、可扩展的多机箱平台,在统一的管理域中管理所有资源(图1)
思科 UCS B 系列刀片服务器是思科统一计算系统的重要构建模块,为当今和未来的数据中心提供了灵活、可扩展的计算能力,同时能够帮助降低总体拥有成本(TCO)。
思科 UCS B 系列刀片服务器构建于工业标准服务器技术基础之上,提供有以下特性:
· 多达两个英特尔至强系列 5500或5600 多核处理器。
· 两个可选前置热插拔 SAS 硬盘。
· 支持多达两个双端口扩展卡连接,可提供高达 40 Gbps 的冗余I/O 吞吐率。
· 工业标准 DDR3 内存。
· 通过集成服务处理器实现远程管理,并可执行在 思科 UCS Manager 软件中制定的策略。
· 通过每台服务器前面板上的控制台端口使用本机键盘、显示器和鼠标(KVM)。
· 通过远程 KVM、安全外壳(SSH)协议、虚拟介质(vMedia)以及IPMI 协议实现带外管理。
思科 UCS B 系列包括两款刀片服务器产品:Cisco UCS B200 双插槽刀片服务器与UCS B250 双插槽内存扩展刀片服务器(图2)。
思科 UCS B200 是一款半宽刀片服务器,拥有12 个DIMM 插槽,可支持高达96 GB 的内存,同时还可支持一个扩展卡。思科 UCS B250 M1 是一款全 宽刀片服务器,拥有48 个DIMM 插槽,可支持高达384 GB 的内存,同时还可支持两个扩展卡。
目前,思科已经推出基于最新Intel XEON芯片的4路 CPU服务器,能满足用户应用性能的不同要求。
9.2
云计算的基础----思科UCS Manager简介
思科统一计算的核心组件之一---Cisco UCS Manager 采用了思科独创的服务配置文件(Service Profile)技术。这一技术用于配置Cisco UCS B 系列刀片服务器及其I/O 属性(如需了解更多信息,请参阅《Cisco UCS Manager 概览》)。服务配置文件中包含了配置服务器和部署应用所需的基础设施策略,包括用于功耗与冷却、安全、身份、硬件状况、以及以太网和存储网络的策略等。通过使用服务配置文件,可以减少手动配置步骤,降低人为错误几率,同时缩短服务器和网络部署时间。此外,服务配置文件还能够在整个思科统一计算系统中改进策略一致性和连贯性。
思科 UCS Manager 创建了一个统一的管理域,这可视为思科统一计算系统的中枢系统。思科 UCS Manager 是嵌入式设备管理软件,通过一个直观的图形用户界面(GUI)、命令行界面(CLI)或XMLAPI,作为单一逻辑实体对系统进行端到端管理。
思科 UCS Manager 的关键特性在于,它使用服务配置文件来配置思科统一计算系统资源。服务配置文件概念可提高IT 工作效率和业务灵活性。现在,基础设施可以在几分钟内配置完成,而不必再花费数天时间,从而使IT 人员的关注重点能够从维护转向战略计划工作。
思科 UCS Manager 使用服务配置文件来配置服务器及其I/O 连接。服务配置文件由服务器、网络和存储管理员创建,并存储在Cisco UCS 6100 系列互联阵列中。在当今的数据中心,服务器很难部署和改变使用目的,因为这通常要花费几天甚至几周的时间来实施。这一问题的出现是因为服务器、网络和存储团队需要仔细的人工协调,来确保其所有设备都能实现互操作。服务配置文件允许将思科统一计算系统中的服务器视作“裸计算能力”,在应用工作负载中进行分配和重新分配,从而能够更加动态、高效地使用当今数据中心内的服务器处理能力。
“裸计算能力”这个概念和技术是实现云计算的关键概念之一。通过这个创新的技术,服务器的物理位置已经不再重要,这为服务器的灵活调用提供了实现的可能。思科UCS Manager将每台服务器上众多的唯一性的物理参数抽象化,如MAC地址,WWPN和WWNN以及UUID等参数,并将其和实体服务器剥离开,使得每台实体服务器不再具有唯一性的参数,成为只有CPU和内存的“裸计算能力”,这样,实体服务器在那个机箱已经不再重要。思科UCS Manager使用服务配置文件来规定一台服务器所必需的物理参数如MAC地址,WWPN和WWNN,以及该服务器应属于哪个VLAN和SAN,当需要一台实体服务器投入使用时,只需将配置文件和某实体服务器关联,则该实体服务器就具有所需的唯一性参数,并可投入使用。关联过程中无需考虑服务器的具体位置,只需考虑其物理配置(如CPU型号,内存大小等)即可,其操作可通过思科UCS Manager的图形化界面,也可以通过XML的API由第三方软件来实现。
通过这种方式,思科统一计算系统将大大简化服务器的部署,并实现资源的灵活调用。当一台实体服务器需要在不同应用场合切换时,如从应用一切换到应用二,只需改变服务配置文件,而服务器本身的物理位置将不会有任何变化,同时,网络连接和SAN连接也无需做任何物理上的重新跳线或布线,因为服务配置文件已经标注好各种应用所属的不同VLAN和VSAN,当实体服务器和配置文件关联后,该服务器就会自动接入到实现定义好的VLAN和VSAN里。事实上,“一次布线”是思科UCS设计时就考虑的一个重要方面。只要不是物理损坏,思科UCS就能保证在任意配置下都能保持网络和SAN的连通性,不必做任何物理连接上的更改。
思科 UCS Manager 安装在一对Cisco UCS 6100 系列互联阵列之上,使用主/被动集群配置来实现高可用性。该管理器不仅要参与服务器配置工作,还要参与设备发现、资产管理、配置、诊断、监控、故障检测、审核及统计数据收集工作。它能够将系统的配置信息导出至配置管理数据库(CMDB),推进基于信息技术基础设施库(ITIL)概念的流程。Cisco UCS Manager 的XML API 还可促进与第三方配置工具之间的协调,以便在使用Cisco UCS Manager 配置的服务器上部署虚拟机和安装操作系统与应用软件。
在高度整合化和虚拟化的基础上,服务的部署完全不需要物理上的动作,资源在虚拟化平台上可以与物理设施无关的进行分配和整合,这样我们只需要将一定的业务策略输入给智能网络的策略服务器,一切的工作都可以按系统自身最优化的方式进行计算、评估、决策和调配实现。
9.3
云计算的扩展----数据中心的横向扩展
目前的数据中心必须有很强的扩展能力,而同时又不能增加系统管理的难度和复杂性。采用思科统一计算平台可以很好的解决这个问题。当需要扩展时,只要将新的刀片机箱接入6120XP,6120XP上内置的管理软件会自动的发现新的硬件,可以根据事先定义好的服务配置脚本对服务器进行设置,如新服务器应该接入那个VLAN,服务器上的HBA卡或应该接入那个VSAN都可以在几分钟内设置完成。在最大规模的系统时,其管理难度和复杂度都没有增加,下图显示了思科统一计算系统较大规模时的架构示意图,可以看到,虽然服务器数量和刀片机箱数量大大增加,但是,从整体架构上看,没有任何改变---所有服务器和刀片机箱都接入统一交换平台,所有管理都从统一交换平台内置的管理软件实现,同时,完全融合已有的网络和存储环境:
9.4
云计算的安全----纯硬件级的容错
现代数据中心内的设备数量和种类都越来越多,各种应用对设备的可用性要求也各不相同,但总体而言,都希望可用越高越好,但一般来说,计划外的宕机总会存在,这里我们总结了引起或需要宕机的若干个关键因素:
· 有计划的维护
· 元器件失效
· 软件故障
· 操作失误
· 楼宇级灾难
· 城市级灾难
为了最大限度的防止诸如元器件失效等引起的意外宕机,通常会使用集群技术来保证应用的持续可用性,下表列举了常用的集群方式:
集群种类
定义和作用
高可用集群
High Availability Cluster – HA Cluster
两台或者两台以上的服务器通过特定HA软件实现对外服务的高可靠性和连续性
负载均衡集群
Load Balance Cluster – LB Cluster
两台或者两台以上的服务器通过特定LB软件实现大规模请求的负载分担和处理
高性能计算集群
High Performance Cluster – HPC
通过大量服务器以及相关HPC专业软件构建起能够完成密集科学计算能力
专业存储集群
Storage Cluster
两台或者两台以上的服务器通过特定存储集群软件实现大容量,高性能的存储服务
通过上表可以看出,目前主流的集群技术都是O/S 等级的集群技术。需要操作系统和应用软件的配合来实现集群和故障切换。对于操作系统层级的集群来说,一般需要用到下面的操作系统。
u Win 2008 server 故障转移集群(Failover Cluster)
u Win 2008 server 网络负载均衡(NLB)
u Redhat 企业集群解决方案(RHCS)
u SUSE Enterprise HA extension
对于应用级的高可用集群,如数据库等应用的方案,需要配合操作系统来实现,一般会用到的数据库集群如下表所示。
u SQL 2008 故障转移
u SQL 2008 数据库镜像
u Oracle Real Application Cluster( RAC )
综上所述,实现传统意义上的高可用性解决方案需要:
ü 软件的支持(OS集群软件、应用软件集群)
ü 复杂的设计和配置
ü 专业的培训
而上述需求意味着:
ü 更高的软件成本
ü 更高的维护和管理成本
ü 更高的技术要求和专业培训
在更多的时候,客户寻求更加经济和灵活的实现方法,实现业务的可用性。 特别是当应用不支持常见集群的时候。通常用户自己开发的应用并没有考虑到集群的特殊需求,并不是为集群这个特殊的环境开发的,而修改代码意味着大量的开发工作和测试,用户往往无法承担如此巨大的费用开销和时间花费。
思科UCS可以实现传统意义上的全部的高可用性解决方案。但是,思科能够提供更为灵活和经济的可用性解决方案,帮助客户实现基本的应用可用性的需求。
由于思科独特的“裸计算能力”和服务配置文件的概念,实现硬件级的容错将不再是高不可攀。服务配置里预先定义好的内容包括:Service Profile,服务器属性的抽象,包括:网络身份信息、MAC 地址、WWN、RAID 信息、IO接口类型及配置、Firmware 版本、启动顺序, 启动LUNs、网络连接特性( VLan, QoS, VSan)等。服务配置文件为已有的应用提供完整的网络和计算资源的所必须的信息, 帮助客户实现在动态的计算环境中实现快速部署和迁移。
当用户针对已有的应用建立独立于服务器的服务配置文件后,将其关联到一个服务器组而不是单个服务器上,这是服务配置文件会寻找该组内可用的服务器资源,由于各服务器都是“裸计算资源”,物理服务器具体位于什么地方对服务配置文件来说并无本质区别。当关联完成后,服务器就可以投入使用。
在正常工作过程当中, 如果该服务器出现故障,可以简单的将该服务器的配置文件关联到组内其他可用服务器上重新启动,无需任何其他配置即可运行。由于配置文件内定义的都是唯一性的物理参数,当新服务器和配置文件关联后,它就具有故障服务器的所有物理参数,这样,无需调整系统内的任何参数如VLAN,VSAN,启动顺序等,新服务器只需重启2-3次就可实现操作系统重启和应用重启,重启后用户应用就可继续服务
。这样,通过服务配置文件的重新关联就可大大降低服务器的重新部署时间, 更重要的是,这样的故障切换无需任何软件(操作系统或用户应用)的参与,是纯硬件实现,因此,特别适合云计算这种既允许单台服务器短时间中断,又需要故障切换的需求。
硬件级的容错使得用户不用采购昂贵的集群软件,也不需要用户掌握复杂的技术实力实施和维护复杂的集群系统,更重要的是,用户的应用无需做任何改动即可实现。就目前的技术来讲,只有思科的“裸计算能力”和服务配置文件才能实现。
第10章
两种数据中心技术方案的综合对比
根据以上对两套方案的详细描述,我们在此进行横向对比和总结。我们将不仅仅限于技术,而从包括对用户的服务到商务条件在内全方位的进行对比。
10.1
技术方案对比
在技术上,我们除了传统上的从性能、可扩展性、安全、可靠性和可管理性等方面进行对比以外,还需要根据前面对新一代数据中心的技术发展要求的阐述,从如何适应XX建设新一代的适于SOA业务能力的数据中心要求出发,按面向服务的数据中心的技术要求进行对比分析,这些技术要求在前面有过详细描述,分别是:整合化,虚拟化、自动化和绿色数据中心能力。下面一一进行比较分析。
10.1.1 传统技术领域对比
类别
方案1:DCE方案
方案2:传统以太网方案
性能
核心和汇聚的性能
- N7000是4.1Tbps;
- 100G以太网平台;
- 每插槽230Gbps;
- Cat6500是720Gbps;
- 10G以太网平台;
- 每插槽80Gbps;
接入层性能
- 万兆端口全线性;
- 千兆端口基本线性(1.2:1);
- 万兆端口2:1过载;
- 千兆端口2.4:1过载;
总体服务质量
- 先进的软硬件机制,保证不丢包的以太网
- 有先进的QoS机制,尽可能少的丢弃
可扩展
核心和汇聚
- 单机箱可扩展到15T以上;
- 每插槽可扩展到500G;
- 单机箱可扩展1.44T以上;
- 每插槽可扩展到160G;
接入层
- 40个万兆固定端口,可扩展至52万兆端口,全部已经为FCoE端口;
- 可扩展FiberChannel端口;
- 本次已经配满,无法扩展;
- 不支持FCoE和Fiber Channel技术;
可靠性
核心和汇聚
- NX-OS操作系统的稳定性,更彻底的多线程保护机制;
- 支持vPC技术保证双核心可靠性;
- IOS模块化操作系统,微核结构,比传统IOS的进程保护能力增强;
- VSS技术保证双网可靠性;
接入层
- 所有接入层支持双电源、可在线更换的风扇系统;
- NX-OS操作系统,稳定的模块化操作系统
- 所有接入层支持双电源、可在线更换的风扇系统;
- 传统IOS,不支持模块化操作系统
安全性
核心和汇聚
- 分布式控制平面保护能力
- 集中式控制平面保护
接入层
- 丰富的二层安全机制
- 不支持三层安全保护机制
- 丰富的二层安全机制
- 丰富的三层安全机制
可管理性
核心和汇聚
- vDC能力
- vPC能力
- 普通终端Console口
- 特殊的无需协议栈的网管端口
- 被管理物理实体2套,管理简单
- VSS能力
- VSS能力
- 普通终端Console口
- 无专用网管端口
- 被管理物理实体4套,管理复杂
接入层
- 采用FEX(虚拟交换矩阵延展),通过N5000管理N2000
- 被管理实体4套,管理简单
- 无FEX虚拟延展功能
- 被管理实体20套,管理复杂
管理系统
- CiscoWorks
- Cisco Fabric Manager
- Cisco Data Center Network Manager
- CiscoWorks
管理成熟性
- 已部署1000多套,正逐步成熟
- 多年验证的成熟性保证
10.1.2 下一代数据中心技术能力比较
类别
方案1:DCE方案
方案2:传统以太网方案
整合化
一体化交换能力
- 支持一体化交换技术:数据以太网、高性能计算网络、存储局域网(SAN)三网整合
- 数据以太网单一技术
- 支持ANSI FCoE标准
- 实现高带宽、大容量、低延迟、无丢弃技术,整合SAN网络
- 实现高带宽、大容量、低延迟、无丢弃技术,代替InfiniBand技术
无丢弃的以太网技术
- 支持优先流量控制(根据优先级的暂停帧支持)
- 支持IEEE 802.1Qaz(带宽管理)
- 移植SAN Credit技术实现帧流控
- IEEE 802.1Qau 标准的拥塞管理(BCN/QCN)
- 无区分的普通暂停帧技术
- 不支持IEEE 802.1Qaz
- 无精确帧流控技术
- 传统基于IP QoS和IEEE 802.1p的排队和流量管理
低延迟
- 端口到端口的低延迟能力(二层3us,三层30us)
- 传统以太网机技术的存储转发方式的延迟
高吞吐能力
- 面向100G以太网的技术
- 4T~15T吞吐能力
- 面向10G以太网的技术
- 720G~1.44T的吞吐能力
虚拟化
系统虚拟化
- 使用VDC(虚拟设备)和VSS(虚拟交换系统)两种技术
Ø 核心和汇聚采用VDC
Ø 智能服务机箱使用VSS
- 核心和汇聚只支持VSS,不支持VDC
网络虚拟化
- 支持VSS和VPC
- 只支持VSS
网络智能服务虚拟化
- 防火墙系统、负载均衡系统等支持虚拟化
- 防火墙系统、负载均衡系统等支持虚拟化
服务器虚拟化
- 一体化交换保证存储和计算资源整合程度高
- 网络支持VN-link,有虚拟机策略迁移能力
- 提供高吞吐、低延迟、可扩展的二层接入环境,利于虚拟机迁移
- 不支持高资源整合度的的服务器虚拟化
- 不支持VN-link,无虚拟机意识
- 提供可扩展的三层环境,适于传统业务应用,不适于虚拟机环境
自动化
业务部署自动化
- 一体化交换、资源整合能力,具备虚拟机意识的虚拟化能力,保证基于服务器和应用业务部署的自动化实现
- 不支持一体化交换和虚拟机网络,只能在网络功能部分实现自动化,很难实现服务器和业务应用部署的自动化
绿色数据中心
资源利用率
- VDC技术减少核心和汇聚设备的硬件数量,资源复用率高
- 支持一体化交换技术,减少网络硬件和服务器网卡数量,提高硬件复用率,减少能耗
- 汇聚层设备可以整合智能服务功能,硬件整合能力比传统网络提高,但需要1+1的6000W大功率电源支撑
- 无一体化交换能力
低能耗半导体工艺
- 基本采用专业设计定制的芯片,不使用通用芯片,避免通用器件中大量无用器件的能耗
- 采用更新的低能耗半导体工艺,整合FCoE的Nuova芯片以太网网卡比分立的以太网卡和存储HBA卡能耗更低
- 基本采用专业设计定制的芯片,不使用通用芯片,避免通用器件中大量无用器件的能耗
- 所采用的半导体工艺比DCE稍早,能耗表现稍逊,且不支持FCoE
设备送风方式
- 专为高密度数据中心机房设计,从核心到接入都按最新的数据中心机房制冷方式优化
- 侧送风,适于传统低密度机房。
万兆端口能耗
- 专为高密度万兆端口设计,接入层采用分布式交换矩阵延展技术,减少万兆布线距离,可大量采用低能耗、低成本的10GE BASE - CU SFP+线缆
- 传统万兆接口,不支持10GBASE-CU SFP+线缆,不适于接入层高密度部署
接入层产品定位
- 按新一代虚拟化数据中心优化,其接入层设备具备高密度万兆线和千兆的线性处理能力,适于运行VMware等平台,但去掉功耗较大、接入层不需要的功能,如三层交换、复杂的路由协议、MPLS等
- 传统以太网设计思路,高性能、高密度万兆和千兆设备必然是功能复杂的三层路由设备,而三层设备每端口功耗远高于二层设备,也增加了设备和管理成本。
10.2
技术服务对比
类别
方案1:DCE方案
方案2:传统以太网方案
安装实施
- 新技术,原厂承诺与集成商相配合的现场服务
- 传统技术,集成商提供现场服务,原厂对集成商通过开Case实现远程支持
售后技术支持
- 标准的CSSP服务
- 新技术,中国思科售后服务支持中心(TAC)成立专门队伍保证对DCE产品的支持
- 标准的CSSP服务
- 传统技术,TAC走一般性支持流程
备件保修服务
- CSSP规定的标准备件先行服务,从备件数量和备件到达时间上均有保证
- CSSP规定的标准备件先行服务,从备件数量和备件到达时间上均有保证
概念验证服务
- 对DCE技术能够提供远程客户概念验证测试中心服务(CPOC服务)
- 无该项服务
10.3
商务对比
类别
方案1:DCE方案
方案2:传统以太网方案
一次性投资
- 与传统相近,略低
- 略高于DCE方案
运行能耗
- 低
- 中
维护管理
- 物理设备少,二层结构简单,维护成本可控
- 传统技术,维护管理成本可控
升级扩展
- 100GE-ready,未来扩展成本低
- FCoE系统,未来融合成本低
- 万兆服务器扩展能力强
- 100GE扩展需更换核心设备
- SAN网和当前数据网分离,当前设备无法实现未来融合
- 万兆接入成本较DCE方案高,万兆服务器扩展能力弱
10.4
总结
根据以上对比,在技术上,方案1的DCE适于新型的准备容纳更多万兆服务器、更高性能存储网络、有VMware虚拟化服务器需求的大型数据中心;而方案2则更适于
没有或较少万兆接入、不准备使用光纤通道技术做存储网络、不准备使用虚拟机技术的传统数据中心。
而在商务上则刚好是如果需求只需要传统数据中心,则方案2具备更高的性价比,而如果需求是新型数据中心,则按同样的配置要求下(比如本次数据中心的端口需求)反而方案1的价格要比方案2的价格低很多。
在服务方面显然方案1能够获得的原厂支持和重视程度要大于方案2,这在很大程度上弥补了方案1的产品投放时间短、技术较新的顾虑。
由于XX已经制定了向新一代面向服务业务架构的数据中心转变的既定发展目标,而方案1无疑是在技术上实现这一目标的最佳解决方案,并且其同时又有在服务和商务上相对于方案2的多重优势,因此我们向用户郑重推荐采用方案1作为本次XX新一代数据中心的建设方案。
第11章
附录:新一代数据中心产品介绍
11.1
Cisco Nexus 7000 系列10插槽交换机介绍
产品概述
Cisco® Nexus 7000系列交换机最大限度地集成可扩展性和运营灵活性。
Cisco Nexus 7000系列交换机是一个模块化数据中心级产品系列,适用于高度可扩展的万兆以太网网络,其交换矩阵架构的速度能扩展至15Tbps以上。 它的设计旨在满足大多数关键任务数据中心的要求,提供永续的系统运营和无所不在的虚拟化服务。Cisco Nexus 7000系列建立在一个成熟的操作系统上,借助增强特性提供实时系统升级,以及出色的可管理性和可维护性。 它的创新设计专门用于支持端到端数据中心连接,将IP、存储和IPC网络整合到单一以太网交换矩阵之上。
作为第一款下一代交换机平台,Cisco Nexus 7000系列10插槽机箱(图1)提供集成永续性,以及专为数据中心可用性、可靠性、可扩展性和易管理性而优化的特性。
· 图1.
Cisco Nexus 7000系列10插槽机箱.
特性和优势
在Cisco NX-OS软件的支持下,Cisco Nexus 7000系列10插槽机箱为数据中心提供一系列丰富的特性,保证系统的永续运营。
· 前后通风,带10个前面板接入的垂直模块插槽和一个集成电缆管理系统,能够支持新老数据中心的安装、运营和冷却。
· 面向数据中心的高可靠性和最高可用性设计方法,所有接口和控制引擎模块都采取前面板接入,冗余电源、风扇和交换矩阵模块则完全采用后端接入,以确保维护过程中布线不受影响。
· 系统采用两个专用控制引擎模块;可扩展、完全分布式的交换矩阵架构最多能容纳5个后端安装的交换矩阵模块,配合10插槽机型的机箱中板设计,整个系统能提供最高7 Tbps的转发能力。
· 拥有8个I/O模块插槽的Cisco Nexus 7000系列10插槽机箱最多支持256个万兆以太网或384个千兆以太网端口,能够满足最大型数据中心的部署需求。
· 前后通风确保Cisco Nexus 7000系列10插槽机箱能用于数据中心,并满足热通道和冷通道部署要求,而不会增加复杂性。它分别采用两个系统风扇架和两个交换矩阵风扇架进行冷却。每个风扇架都配备有冗余风扇,独立变速风扇能随着周围温度自动调整,不仅降低进行出色管理的设施的能耗,而且能实现最佳交换机运行状态。该系统为所有风扇架设计冗余功能,进行热插拔时不会影响系统;如果一个风扇或风扇架发生故障,系统能继续运行,不会对冷却效果造成重大影响。
· 集成电缆管理架能将所有电缆正确、整齐地放在一边或两边。
· 系统拥有可选的空气过滤器,能确保流过系统的空气清洁。添加空气过滤器能满足NEBS要求。
· 机箱顶端的一系列LED清晰地提供主要系统组件的状态显示,能提示操作员是否需要执行进一步的调查。这些LED负责报告电源、风扇、交换矩阵、控制引擎和I/O模块的状态。
· 电缆管理盖和可选的模块前门能使安装在系统中的布线和模块不受意外事件的影响。透明的前门使客户能够查看布线、模块指示灯和状态指示灯情况。
11.2
Cisco Nexus 5000 / 2000系列交换机介绍
产品概述
Ciscoâ Nexus 5000系列是一个为数据中心应用提供支持的线速、低延迟、零丢包万兆以太网,思科数据中心以太网和以太网光纤通道(FCoE)交换机(参见图1)。
图1. Cisco Nexus 5000系列包括支持万兆以太网、思科数据中心以太网和FCoE的Cisco Nexus 5020
在当今的数据中心中,具有强大的多内核处理器、机架安装的密集刀片服务器日益增多。机架内计算密度的激增,以及虚拟化软件的普及,都推动对于万兆以太网和整合I/O的需要: Cisco Nexus 5000系列能完美地支持这一应用。Cisco Nexus 5000系列具有延迟低、前后通风及后面板端口的特点,适用于正要迁移到万兆以太网的数据中心,以及那些已准备部署统一阵列,以支持通过单一链路联网的局域网、存储局域网和服务器集群(或采用双链路实现冗余)的数据中心。
此交换机系列使用简洁的架构,在所有端口上支持万兆以太网,而且无论数据包大小和实施何种服务,都保持一致的低延迟。它支持思科数据中心以太网功能,提高以太网的可靠性、效率和可扩展性。这些特性使该交换机可在一个无损耗的以太网阵列上,支持多个流量类别,由此实现局域网、存储局域网和集群环境的整合。它能将FCoE连接到本地光纤通道,保护现有存储系统投资,并大大简化机架内布线。除在服务器上支持标准万兆以太网卡(NIC)外,Cisco Nexus 5000系列能与融合网络适配器(CNA)的整合式I/O适配器集成,将以太网NIC与光纤通道主机总线适配器(HBA)相结合,透明地迁移到一个统一网络阵列,与现有实践、管理软件和OS驱动程序协调一致。此交换机系列与第三方集成收发器和Twinax布线解决方案集成,在机架级别为服务器提供非常经济高效的万兆以太网连接,无需再使用昂贵的光收发器。
无论实施哪些网络服务以及数据包大小如何,Cisco Nexus 5000系列交换机阵列使用的简洁技术都能支持统一的低延迟以太网解决方案。该产品系列专为数据中心环境而设计,采用前后通风,网络端口位于后部,使交换操作更贴近服务器,并尽量简化和缩短布线。此交换机系列非常便于维护,采用冗余、可热插拔的电源及风扇模块。其软件以数据中心级Cisco NX-OS软件为基础,提供高可靠性和易管理性。
Cisco Nexus 5020 56端口交换机
Cisco Nexus 5020是一款2机架单元(2RU)、万兆以太网、思科数据中心以太网和FCoE 1/2/4 Gbps光纤通道交换机,能够以极低延迟提供1.04Tbps吞吐率。它有40个固定万兆以太网、思科数据中心以太网和FCoE SFP+端口。通过配置,2个扩展模块插槽能增加支持12个万兆以太网、思科数据中心以太网和FCoE SFP+端口、多达16个光纤通道交换机端口,或二者的结合。该交换机有1个串行控制台端口和1个带外10/100/1000 Mbps以太网管理端口。它采用可热插拔的1+1冗余电源,以及可热插拔的4+1冗余风扇模块,以提供高可靠的前后通风。
扩展模块选项
Cisco Nexus 5000系列能够支持扩展模块,以增加万兆以太网、思科数据中心以太网和FCoE端口的数目;或经由1/2/4 Gbps光纤通道交换机端口连接到光纤通道存储局域网(SAN);或实现这两个目的。Cisco Nexus 5020支持以下任意两个模块的组合(参见图2):
l 1个以太网模块,提供6个万兆以太网、思科数据中心以太网和FCoE SFP+端口。
l 1个光纤通道和以太网模块,提供4个万兆以太网、思科数据中心以太网和FCoE SFP+端口,以及4个经由SFP接口提供
1/2/4 Gbps本地光纤通道连接的端口。
l 1个光纤通道模块,提供8个经由SFP接口提供1/2/4 Gbps本地光纤通道的端口,以便透明连接现有光纤通道网络(未来提供)。
图2. 从左到右:6端口万兆以太网、思科数据中心以太网和FCoE模块;4端口光纤通道和4端口万兆以太网、思科数据中心以太网和FCoE模块;8端口本地光纤通道扩展模块
高效的收发器和布线选项
万兆以太网的高带宽对传输提出巨大挑战,而现在这已被Cisco Nexus 5000的收发器和布线选项所克服。该产品系列支持一个创新的Twinax铜布线解决方案,它连接标准SFP+连接器以便机架内使用,并为较长的电缆提供光布线(参见图3)。
l 对于机架内布线或邻接机架布线,Cisco Nexus 5000系列支持SFP+直连式万兆以太网铜缆,这个创新解决方案将收发器和Twinax电缆集成到一个节能、低成本、低延迟的解决方案中。SFP+直连式万兆以太网Twinax铜缆每收发器仅使用0.1瓦(W)功率,每链路大约只有0.25微秒的延迟。
l 如需进行较长布线,Cisco Nexus 5000系列还支持多模、短距离SFP+光收发器。每个光收发器的功率大约1W,延迟不到0.1微秒。
这两种选项与10GBASE-T相比,延迟更短,能效更高。10GBASE-T标准使用功率在4到8W之间的收发器,每链路延迟高达2.5微秒,很大程度上增加网络级功耗。
图3. Cisco Nexus 5000 系列使用SFP+直连式万兆以太网铜缆进行机架内布线,使用光传输解决方案来支持更长连接
技术
电缆
距离
电源(每边)
收发器延迟(链路)
SFP+铜缆
SFP+USR超短距离传输
SFP+SR短距离传输
与整合式适配器兼容
思科及其合作伙伴已开发CAN,为服务器操作系统提供一个以太网NIC和一个光纤通道HBA,使IT部门能以完全透明的方式,使用与这两个网络相同的操作系统驱动程序、管理软件和最佳实践,来部署
FCoE。这些适配器参与交换机自动协商,简化管理并有助于减少配置错误。Emulex和Qlogic提供基于ASIC的定制融合网络适配器,Intel则提供基于软件的融合网络适配器。
Nexus 2000——Nexus 5000的交换矩阵延展器
为了将Nexus 5000的服务延展到更多机柜,提供更高密度的DCE接入,但又无需增加管理上的负担,思科提供了Nexus 2000——Nexus5000专用的延展器,它提供高密度的千兆或万兆本地接入,然后用几乎线性的性能完成万兆的上连,而所有管理则完全放在上连的Nexus5000上,从而提供了最佳性价比、且支持VN-link等高级DCE功能的数据中心接入解决方案。
11.3
Cisco NX-OS 数据中心级操作系统简介
产品概述
Cisco NX-OS是一个数据中心级的操作系统,该操作系统体现模块化设计、永续性和可维护性。在业界成熟的Cisco SAN-OS软件的基础上,Cisco NX-OS确保持续的可用性,并为承担关键业务的数据中心环境设立标准。Cisco NX-OS的自行恢复和高度模块化的设计实现对业务无影响的运行,提供出色的运营灵活性。
Cisco NX-OS是面向数据中心的需要而设计的,它所提供的强大、丰富的特性集,不仅能满足当前数据中心的路由、交换和存储网络要求,还能满足未来的数据中心需求。凭借XML界面和类似Cisco IOS®软件的CLI,Cisco NX-OS为相关网络标准和各种真正数据中心级思科创新的实施提供鼎力支持。
特性和优势
灵活性和可扩展性
· 软件兼容性:Cisco NX-OS 4.0能与运行各种Cisco IOS软件操作系统的思科产品互操作。Cisco NX-OS 4.0也能与遵循本产品简介中所列举的网络标准的网络OS互操作。
· 整个数据中心通用的软件:Cisco NX-OS简化数据中心的操作环境,提供一个统一的OS,能够在数据中心网络的各个区域运行,包括局域网、SAN和第四到七层网络服务。
· 模块化软件设计:Cisco NX-OS能够在SMP、多核CPU和分布式线卡处理器上支持分布式多线程处理功能。硬件表编程等需要大量计算的任务能卸载给分布在多个线卡上的专用处理器。Cisco NX-OS模块化进程在独立受保护内存空间中逐个按需启用。因此,只有当一个特性启用后,进程才会启动,开始分配系统资源。模块化进程由实时预先排程器管理,有助于确保及时处理关键功能。
· 虚拟设备环境(VDC):Cisco NX-OS能够将OS和硬件资源划分为模拟虚拟设备的虚拟环境。每个VDC拥有其自身的软件进程、专用硬件资源(接口)和独立的管理环境。VDC有助于将分立网络整合为一个通用基础设施,保留物理上独立的网络的管理界限划分和故障隔离特性,并提供单一基础设施所拥有的多种运营成本优势。
可用性
· 持续系统运营:Cisco NX-OS提供持续的系统运营,维护、升级和部署软件认证,同时不会造成服务中断。通过将进程模块化、模块化修补、思科运行中软件升级(ISSU)功能和不间断转发(NSF)平稳重启相结合,极大地降低软件升级和其他操作所带来的影响。
· 思科ISSU:思科ISSU利用冗余引擎在平台上提供透明的软件升级功能,极大地缩短停机时间,使客户能够在极少影响或不影响网络运营的情况下,集成最新的特性和功能。
· 迅速开发增强特性和故障修复:Cisco NX-OS的模块化特性使新的特性、增强特性和故障修复能够迅速地集成入软件。因此,模块化修复功能能够在极短的时间内完成开发、测试和交付使用,满足紧迫的时间要求。利用ISSU,这些更新镜像能在不干扰正常运行的情况下安装。
· 进程应急启动:关键进程在受保护的内存空间中运行,独立于其他进程和内核,从而提供精确的服务分隔和故障隔离,支持模块化修补和升级,以及快速重启功能。各进程能够分别重启,不会丢失状态信息,不会影响数据转发,因此,在升级或故障后,进程会
在数毫秒内重启,而不会影响邻近的设备或服务。利用基于标准的NSF平稳重启机制,拥有大量状态信息(如IP路由协议)的进程能够得以重启;其他进程则借助本地永久存储服务(PSS)维持其状态。
· 状态化引擎故障切换:冗余引擎始终保持同步,支持快速的状态化引擎故障切换。它具有先进的检验功能,有助于确保故障切换后整个分布式架构中状态的统一性和可靠性。
· 可靠的进程间通信:Cisco NX-OS提供进程间可靠的通信功能,能够确保故障过程中和出现不利情况下,所有信息都得以传送和正确地发挥作用。该通信功能有助于确保进程同步化和状态的一致性,这些进程能够在分布于多个引擎和I/O模块上的处理器上启用。
· 冗余交换以太网带外信道(EOBC):Cisco NX-OS能充分利用冗余EOBC来支持控制和I/O模块处理器间的通信。
· 基于网络的可用性:通过提供工具和功能,使故障切换和回退透明、迅速,从而优化网络收敛。例如,Cisco NX-OS提供生成树协议增强特性,如BPDU防护、环路防护、根防护、BPDU过滤器和网桥保证,以确保生成树协议控制平面的状态正常;UDLD协议;路由协议NSF平稳重启;毫秒间隔的FHRP;SPF优化,如LSA Pacing和iSPF;以及带可调整计数器的IEEE 802.3ad链路汇聚。
可维护性
· 故障排除和诊断:Cisco NX-OS拥有独特的可维护性功能,使网络操作员能够根据网络趋势和事件提前采取行动,从而增强网络规划,缩短网络运营中心(NOC)和厂商的响应时间。呼叫到家、思科通用在线诊断(GOLD)和Cisco NX-OS嵌入式事件管理器(EEM)是Cisco NX-OS用于提高可维护性的部分特性。
· 交换端口分析器(SPAN):SPAN特性允许管理员在不对运营造成影响的情况下,将SPAN进程流量导向连接一个外部分析器的SPAN目的地端口,从而对端口(称为SPAN源端口)间的所有流量进行分析。
· 嵌入式数据包分析器:Cisco NX-OS拥有一个内置数据包分析器,用于控制平面流量的监控和故障排除。该数据包分析器以常用的Wireshark开放源网络协议分析器为基础而构建。
· 智能呼叫到家:智能呼叫到家特性能够持续监控软硬件,并通过电子邮件发送关键系统事件通知。它拥有多种消息格式,能与寻呼机服务、标准电子邮件和基于XML的自动分析应用等出色兼容。它提供报警分组功能和可定制目的地功能。该特性有多种用途,例如直接寻呼网络支持工程师、发送电子邮件给NOC,以及利用思科自动通知服务直接开启一个思科技术支持中心(TAC)案例等。这一特性向实现自治系统运营迈出重要的一步,使网络设备在出现问题时能通知IT,确保故障得以迅速地解决,缩短解决时间,最大限度地延长系统正常运行时间。
· 思科GOLD: 思科GOLD是一个诊断套件,负责检验硬件和内部数据路径是否按设计要求运行。思科GOLD特性集包括引导时间诊断、持续监控,以及按需和定期测试等。这个业界领先的诊断子系统能够执行对当今连续运行环境十分重要的快速故障隔离和持续系统监控功能。
· 思科EEM: 思科EEM是一项强大的设备和系统管理技术,集成在Cisco NX-OS之中。思科EEM能够帮助客户充分利用思科软件的网络智能优势,使其能根据发生的网络事件,定制所采取的行动。
· Cisco Netflow: Netflow是Cisco NX-OS中的一个组件,它支持版本5和版本9输出,以及灵活Netflow配置模式和基于硬件的样本Netflow,提高可扩展性。
可管理性
· 可编程XML界面:在NETCONF业界标准的基础上,Cisco NX-OS XML界面为设备提供一个统一的API,使客户能快速开发和创建工具,增强网络性能。
· SNMP协议:Cisco NX-OS符合SNMP版本1、2和3的规定,支持广泛的管理信息库(MIB)。
· 配置验证和回退:凭借Cisco NX-OS,系统操作员能够在应用配置前,验证配置的一致性和所需硬件资源的可用性。因此,设备能预配置,之后再应用经过验证的配置。配置还包括检查点,以使管理员能根据需要回退到以前的完善配置。
· 基于角色的访问控制(RBAC):凭借RBAC,Cisco NX-OS使管理员能分配用户角色,限制用户对交换机的操作。管理员能够定制接入功能,仅允许必要用户访问网络。
· 思科数据中心网络管理器(DCNM):思科DCNM是一个专门用于数据中心网络运营的管理解决方案。它大幅延长整个数据中心基础设施的正常运行时间,提高可靠性,因而能够支持业务连续性。思科DCNM是为Cisco NX-OS产品系列专门设计的。
· 连接管理处理器(CMP)支持:Cisco NX-OS支持利用CMP对平台实施“熄灯式”远程管理。通过提供NX-OS控制台带外接入信道,CMP为运营提供有力支持。
流量路由、转发和管理
· 以太网交换:Cisco NX-OS支持高密度、高性能的以太网系统,提供全面的数据中心级以太网交换特性集。该特性集包括IEEE 802.1D-2004 快速和多生成树协议(802.1w和802.1s)、IEEE 802.1Q VLAN和中继、支持16,000名用户的VLAN、IEEE 802.3ad链路汇聚、私有VLAN、跨机箱私有VLAN、主动和标准模式UDLD,以及流量抑制(单播、组播和广播)。生成树协议利用生成树环境中的ISSU、BPDU防护、环路防护、根防护、BPDU过滤器、网桥保证和巨型帧支持,实现透明升级。
· IP和路由:Cisco NX-OS支持广泛的IP版本4和6 (IPv4和v6)服务及路由协议。这些协议的实施完全符合最新标准的要求,提供先进的增强特性和参数,如4字节ASN和增量SPF,并且无需使用率低下的传统功能,其出色实施能够提高特性速度和系统稳定性。所有单播协议都支持不间断转发平稳重启(NSF-GR)。所有协议都支持各种类型的接口,包括以太网接口、交换虚拟接口(SVI)和子接口、端口信道、隧道接口和环回接口。
· IP组播:Cisco NX-OS提供业界领先的IP组播特性集。Cisco NX-OS 4.0的实施为未来开发支持组播的丰富网络功能奠定基础。
· Cisco NX-OS去除已废弃的功能,如PIM密集模式,这是体现操作系统的前瞻性发展方向的一个实例。
· 服务质量(QoS):Cisco NX-OS支持多种QoS机制,包括分类、标记、队列、监管和调度。所有QoS特性都支持模块化QoS CLI (MQC)。MQC能用于在各种思科平台上提供统一的配置。
网络安全
· Cisco TrustSec: 作为Cisco TrustSec安全套件的一个组件, Cisco NX-OS提供出色的数据保密性和完整性,利用128位高级加密标准(AES)支持标准的IEEE 802.1AE链路层加密。链路层加密保证端到端数据私密性,允许按照加密路径添加安全服务设备。安全组访问控制列表(SGACL)是网络访问控制的一个新模式,是在安全组标记而非IP地址的基础上构建的,能够支持更加精确的策略,且因为具有拓扑结构独立性,使管理更加方便。
· 其他网络安全特性:除Cisco TrustSec以外,Cisco NX-OS 4.0还提供以下安全特性:
- 数据路径入侵检测系统(IDS),用于协议遵从性检查
- 控制平面限速(CoPP)
- MD5路由协议验证
- 思科集成安全特性,包括动态ARP检测(DAI)、DHCP电子欺骗和IP源防护
- AAA和TACACS+
- SSH协议版本2
- SNMPv3支持
- 端口安全
- IEEE 802.1x验证和RADIUS支持
- 第二层思科网络准入控制(NAC)局域网端口IP
- 由命名ACL (基于端口的ACL [PACL]、基于VLAN的ACL [VACL]和基于路由器的ACL [RACL])支持的、基于MAC和IPv4地址的策略