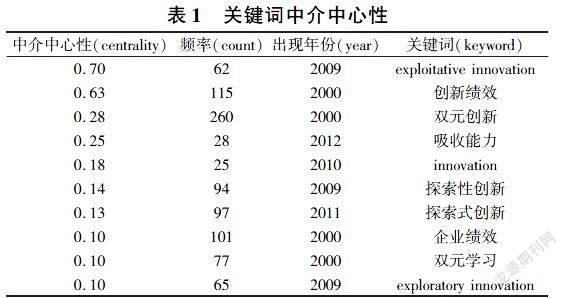
范家杰 宫云平

【摘 要】随着社会的发展,人们对公众场合安全问题越来越重视,对热点区域人流监控的需求日益旺盛。传统的方法是通过摄像头、红外等设备进行监控[1],但是这种方法投入大,耗时耗力,不太适合大范围监控区域。针对这一问题,提出一种基于DPI数据的实时人群分析方案,通过采集用户上网行为形成的海量DPI数据,对DPI数据进行实时解析,可以获得包括地理位置、访问网站、使用时长等信息,然后根据地理位置划分出不同区域,最后按区域进行分类汇总分析,并输出人群分布以及使用爱好等情况。本方案已经成功应用于实际系统,取得良好效果。
【关键词】DPI;结构化流;人群分析
doi:10.3969/j.issn.1006-1010.2020.10.011 中图分类号:TN91
文献标志码:A 文章编号:1006-1010(2020)10-0061-05
引用格式:范家杰,宫云平. 基于DPI数据的人群分析方法及实践[J]. 移动通信, 2020,44(10):
61-65.
0 引言
随着移动互联网的不断发展以及各类智能设备日益深入民众日常生活中,人类社会产生的数据量正在以指数级快速增长,人类已经正式迈入大数据时代[2]。如今,运营商能够获得的用户数据越来越丰富,通过DPI(Deep Packet Inspector,深度分组检测)分析技术,能够较好地识别网络上的流量类别、应用层上的应用种类等[3]。在这个“数据为王”的时代,如何充分利用这笔重要的战略资产已经成为重中之重的问题[4]。
另一方面,随着社会发展,针对热点区域的人群分析也越来越重要。而传统的通过摄像头、红外等设备的监控方法,不仅需要投入巨大的硬件成本、人力成本,而且在显示器能看到的监控区域还很有限,可见传统方法针对大范围的监控力不从心。运营商通过收集用户收集上报的DPI信息,可以获得手机用户的地理位置、上网时长等内容,因此可以通过DPI信息从另一方面感知热点区域人流聚集情况,达到人群分析的目的。
本文结合电信运营商的数据以及人群分析的需求,提出一种基于DPI数据的人群分析方法,能够实时分析DPI数据,提取出其中蕴含的地理位置信息、用户上网信息等,并按不同热点区域进行分类汇总分析。本方法在不增加设备、不增加用户负担的前提下,可以实时获得热门区域人群聚集情况、上网行为等信息,方便进行人员管理以及精准营销,具备极高的性价比。
1 Spark结构化流
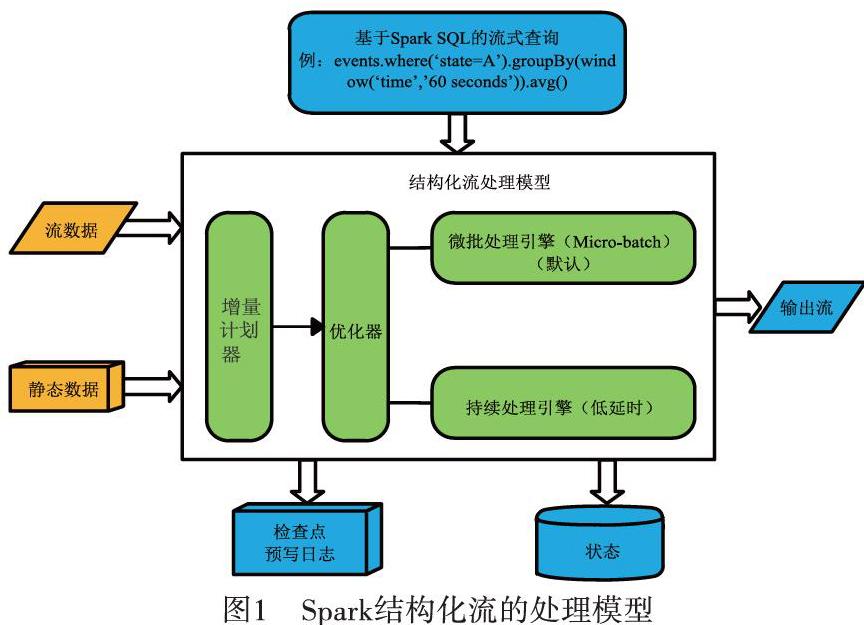
Spark结构化流是一个基于Spark SQL执行引擎的流处理引擎,是Spark 2.X时代新推出的一种流处理框架,目前最新版本为Spark2.4[5]。Spark结构化流具有高可扩展性、高容错性的特点,提供快速、端到端的一次性消费能力[6]。Spark结构化流能非常好地融入现有大数据平台,不需要安装其他软件,集成度高,底层封装了大量接口,对开发能力的要求较低。
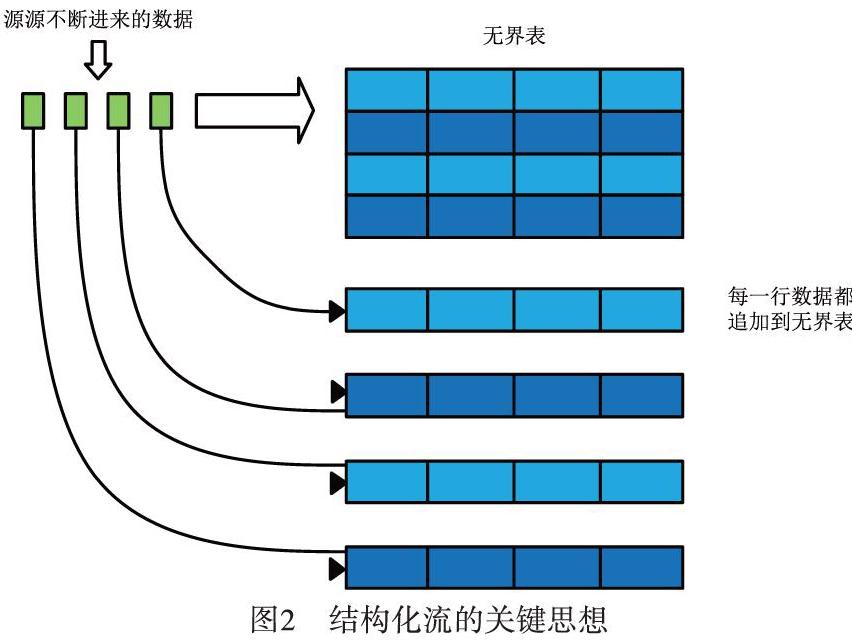
Spark结构化流的处理模型如图1所示。结构化流的关键思想是把实时数据变成一张不断延伸的表格,不断进来的数据追加到该表格,形成一行新数据,如图2所示[7]。所有的操作都是针对这张不断更新无边界的大表,最后把处理结果增量或者全量输出到不同的文件系统或数据库等。
事件时间是事件发生时间而不是数据到达时间[8]。更多情况下流式处理都是针对事件时间,而结构化流原生支持事件时间,也支持基于事件时间窗口的聚合操作[9]。当存在延迟数据时,程序可以设置最大允许延迟时间Watermark,在Watermark内到达的数据都会被统计,而超出部分數据将被抛弃掉,同时自动跟踪数据中的事件时间,相应地清除旧状态。如图3所示。
Spark结构化流使用的前提是数据必须是能够结构化的,在这个基础上,结构化流提供了丰富的、集成度高的API,来对数据进行灵活转换。整个过程具备高可用性、高容错性,以及一次性保证、断点续传的特点,特别适合用来处理能够结构化的数据。
Spark Streaming基于微批次实现了准实时处理(秒级处理时延),也在Spark计算引擎技术栈之中[10]。Spark Streaming可以实现高吞吐量的、具备容错机制的实时流数据的处理,是一种常见的流式框架[11]。Spark Streaming是基于RDD开发的,数据模型是Dstream。而结构化流是基于Sql开发的,数据模型是DataFrame。另外Spark Streaming的处理是基于处理时间,而结构化流是基于事件时间。因此能结构化的数据并且更加关注事件时间的,适合使用Spark结构化流。
2 人群分析方案
本方案如图4所示。设备厂商把包含DPI信息的压缩文件通过Ftp的方式推送到大数据平台,保存在HDFS上。Spark结构化流直接读取并实时分析DPI数据,并将结果输出到HDFS或者Mysql中。
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,可以满足大数据采集的需求。Kafka是一种高吞吐量的分布式发布订阅消息系统,通常用作数据缓存。对于流式处理而言,常见的方案通常会用Flume进行数据采集,用Kafka进行数据缓存,最后流式处理工具去消费Kafka的数据,这样不会因为瞬间的大量数据导致流式计算崩溃。而本文通过自定义的方式直接读取Hdfs文件,这样不仅可以加快处理速度,节省处理时间,还可以减少中间件运维成本。
Spark结构化流程序在遍历根目录寻找最新文件的时候,都会读取到一些过时的文件。虽然结构化流有Watermark机制,但也是把数据读取后再进行过滤,这在处理上有很大的浪费。同时由于缺少数据缓冲,瞬时的大量数据非常容易导致程序崩溃。为了解决这一问题,本文采取改造扫描方式,增加realTime、readHour两个参数直接在读取文件名的时候过滤超时数据,同时通过结构化流的maxFilesPerTrigger参数来控制每次读取文件的数量,通过latestFirst参数来控制优先读取新文件,保证每次处理文件都是最新的。
Spark结构化流需要监控的区域每天都会变,因此需要实时更新配置数据,这样才能及时监控到新区域。为了达到这一目的,程序在不重启的情况下每隔10分钟会去更新配置数据,并同步到Spark的每个节点上,这样每个节点计算时会把新区域监控上。
实时读取到的DPI数据会被切割成不同字段,包括用户号码MDN、基站ECGI、流量FLOW等信息。通过不同基站的组合可以划分出不同的区域,如把广州琶洲展馆附近基站组合在一起,就可以感知到展馆附近人流情况。而根据不同的区域对流量、访问网站等分析,就可以进一步获取该区域人流的行为特征。如在区域A中,通过统计去重用户号码,就可以获取该区域的人流量;通过统计用户访问的网站,即可获取该区域用户上网爱好习惯;通过统计用户使用的手机型号,可以获取该区域的消费能力等,如图5所示。
在结构化流中,数据切割出的字段会映射成一张无边界表,然后使用Sql对临时表进行查询。这些查询统计结果会根据陆续到达的数据而不断更新,达到一定时间阈值后,数据将会被输出到Hdfs或者Mysql。为了更好实现Spark可扩展性强的特点,系统增加了动态SQL注入机制。该机制通过配置文件的形式自定义SQL计数器,程序再将SQL转换成SparkSQL底层代码,并启动计数器计数。同时通过配置文件为每个计数器指定输出通道,将结果输出到指定路径。这样需求人员可以自定义计数器,并把结果输出到想要的位置,可扩展性大大增强。
为了更好观察流式处理系统处理状态,系统引入监控功能。该监控功能可以实时监控程序是否在正常处理文件,同时还可以监控文件是否有积压情况,实时处理性能以及延迟情况。如发现程序状态异常,可以记录系统异常记录同时重启程序,保证程序始终有数据输出。
本文介绍的方案只需要部署一个Spark结构化流组件,即可完成从数据采集、分析、输出全过程,解决了数据更新、数据缓冲、多业务通道、多业务输出的难点,具有运维简单、可靠性强、扩展方便的特点。
3 实践及分析
本项目使用Spark 2.4.0进行开发,资源配置如下:40个Executor实例,每个Executor配置10 G内存和5个Core。根据该资源和实际测试效果,限制了每批次最大处理文件为200个(约20 G,耗时约4分钟),即最高处理效率为每秒8.8万条,且默认优先处理最新的文件。在高峰的情况下,DPI文件个数约为3 500个,DPI文件产生后,2分钟内能输出结果,整体时延在5分钟内。
与文献[4]所述的基于KafkaStream的流式处理方案相比,本文所述方案仅用了400 G内存,而文献[4]使用了6台256 G内存的机器,资源消耗大大减低。同时减少了Flume、Kafka、ELK等一系列组件,降低了运维成本。在时间方面,本文的整体时延仅为5分钟,而文献[4]由于组件多,程序处理逻辑复杂,整体时延将近30分钟,因此本文在资源消耗、耗时等一系列指标均优于基于KafkaStream流式框架。
目前系统日均处理200亿条数据,为70多个区域提供监控能力,并且监控区域在不断增长。目前的SQL统计包含5分钟区域用户数/流量统计,1小时区域用户浏览统计等,另外用户可以通过配置文件自己个性化增加统计功能。
在前端页面应用中,通过统计区域内每小时的去重用户数,可以绘制出人群热力图,直观看到人群聚集情况,如图6所示。通过统计每小时用户使用的App,可以绘制出该区域最常浏览的Top10应用,如图7(a)所示,区域最热应用为微信。通过统计预期内每5分鐘的去重用户数,可以绘制出每5分钟4G上网用户数,如图7(b)所示,9点50分区域内有33名用户同时在线。
本系统已经在广东省试点实施,监控区域包括广州各大热门场所如白云机场、广州南站以及琶洲展馆等。系统连续3年应用于广州春运期间火车站,并为2017年广州财富论坛、第十五届广东省运动会提供监控服务,取得良好效果。
4 存在的问题
在开发过程中,也发现结构化流的一些不足。如一次统计多项业务时,由于结构化流基于Spark SQL的底层,其执行过程是生成逻辑计划,再优化成物理计划执行,因此每项业务得独自统计,形成多个通道,会导致每个通道都各自读取数据源,对于大规模数据而言,带来了大量额外消耗。
在业务层面上,目前应用较少,仅能提供5分钟/1小时维度的关于流量、人数、使用情况的统计,而没有进行更深一步的分析。后期考虑加入人数达到一定阈值触发预警机制,结合用户需求做实时推荐等功能。
5 结束语
本文首先介绍了目前传统监控手段的缺点以及运营商拥有的海量DPI数据,然后结合热点区域人群分析需求和DPI数据,提出一种基于DPI数据的人群分析方法,并概述了Spark结构化流具有高可用性、高容错性、开发简单的特性。该方案已经在实际项目中应用,能够实时分析DPI数据的位置、上网行为等信息,统计5分钟不同区域人流情况以及1小时不同区域访问网站情况,并且在前端页面展示,很好地结合了监控需求以及运营商DPI资源,取得良好的效果。
目前系统应用的计数器偏少,后续可以根据需要增加Sql统计。Spark结构化流是一个新生事物,目前还在迭代优化中,其中不免存在一些问题,对多业务统计不够友好,目前应用的项目不多,中文资料也较少。但瑕不掩瑜,Spark结构化背靠Spark这棵大树,本身性能不弱,并集成了大量API,入门简单,未来前景可期。
参考文献:
[1] 董迦勒. 基于大数据的区域人流监控平台的设计与实现[D]. 北京:
北京交通大学, 2018.
[2] 陈康,付华峥,陈翀,等. 基于DPI的用户兴趣实时分类[J]. 电信科学, 2016,32(12):
109-115.
[3] 孙大为,张广艳,郑纬民. 大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014,25(4):
839-862.
[4] 范家杰,田熙清,郑博. 基于流式计算的DPI数据处理方案及实践[J]. 移动通信, 2018,42(1):
80-86.
[5] NightPxy. [Spark]-结构化流之初识篇(待重修)[EB/OL]. (2018-07-05)[2019-10-08]. https://www.cnblogs.com/NightPxy/p/9271453.html.
[6] 博客园. Spark译文(三)[EB/OL]. (2019-04-29)[2019-10-08]. https://www.cnblogs.com/fenghuoliancheng/p/10790307.html.
[7] Spark. Structured Streaming Programming Guide[EB/OL]. [2019-10-08]. http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html.
[8] 于秀金. 类型学视野下的英汉时体研究[D]. 上海:
上海外国语大学, 2013.
[9] BillowX. StructuredStreaming编程指南[EB/OL]. (2019-01-23)[2019-10-08]. https://www.jianshu.com/p/43d11948ad11.
[10] 韦钰. 一种基于Spark Streaming的实时数据处理方法[C]//2019年全国公共安全通信学术研讨会. 中国通信学会, 2019:
5.
[11] 杨伯宇. 基于Spark Streaming的實时DDoS检测系统[D]. 济南:
山东大学, 2019.