【摘要】 数据传输在异构系统构架中是一个瓶颈问题,类似在计算机系统中的内存墙问题,此类问题的产生是因为,多年来计算机内部存储技术(主要是指内存)一直跟不上处理器技术在延迟和功耗方面的进步,此类问题也被称为“内存墙”(Memorywall)问题,体现近内存计算思想的计算机系统的第一次出现可以追溯到20世纪90年代初,用于数据处理的原型机则由 Kozyrakis 等人提出,当时被称之为矢量 IRAM(VIRAM、)。研究人员开发了一个开发板上嵌入式DRAM(eDRAM)的矢量处理器,用来处理多媒体应用中的数据并行性计算的部分。虽然取得了一定的成果,但这些近内存系统并没有真正渗透到市场,成果仍然有限。其中一个主要原因是技术限制,主要是因为由于计算处理技术和内存技术流程的差异,以及它们能够在矢量处理器集成的芯片上内存大小的限制。
【关键词】 数据传输 程序 计算机加速器
经过近20年的发展,近内存计算系统的研究正在多个技术及社会需求背景下重新引起学界、厂商的关注。这种关注主要归因于以下三个原因。
1.新的内存封装技术的进步,包含3D和2.5D等内存堆叠技术的进步,将一系列逻辑和内存混合在同一包中,带来了了全新的计算机存储介质。
自2011年以来,NVM技术一直非常活跃,其中NVMe协议从目前在单独的协议规范中,出现了三个角度的演变。除了原有的基本NVMe规范之外,NVMe管理接口规范(NVMe-MI),该规范介绍了如何管理通信和设备(设备发现、监视等)和NVMe通过结构规范(NVMe-oF),该规范实现了通过网络驱动与非易失性存储通信。随着时间的推移,随着更多不同行业的用户开始采用NVMe,新用户将描述他们对新功能的需求,并引入规范的新思路。NVMe协议的采用仍在增长,并且正在产生创新。硬件和软件公司正在通过引入新的封装外形、创造的新产品和电器结构等来寻找新的方法来进入传统的内存构架及近内存计算。可以预见NVMe生态系统的重点是为用户提供扩展到数据中心或超大规模基础结构中去。
2.将计算迁移到临近到数据存储的位置,可以绕过内存包引脚计数限制,从而避免数据移动导致的性能和能量瓶颈。
传统的冯诺依曼体系结构数据流向存在的问题是过分的以计算为中心导致的。性能、能耗,等问题一直困扰着这种二元结构,因此新的方法将计算过程迁移到临近到数据存储的位置,也就是说在尽量靠近数据的地方来处理数据或者尽量减少数据的访问来完成计算,从而绕过内存包引脚计数限制,将处理推送到数据中间去或者推送到存储中间去,从而提升性能降低能耗。
3.随着云计算、大数据、物联网、移动互联及区块链在經济活动、社会活动等领域中的应用,现代数据密集型应用的出现,需要更新的计算架构。
研究提出了各种近内存计算体系的设计,并证明了这些设计在提高许多应用场景中的性能提升。在这些研究中,NMC已表现出诸如存内计算(PIM,Processing-in-Memory,也被称为in-memory computing)、近数据处理(NDP,Near data processing)、近内存处理(NMP,Near memory processing)等概念。上述这些概念和计算思路都是为了平衡处理器和存储之间实际上发展的是不平衡的现状,其核心原则是将计算机处理数据的过程更接近内存。这些技术研究进一步打破了内存的物理约束及日益限制了通用处理器性能改进的潜力。这一趋势在登纳德缩放和摩尔定律的当前放缓中已经很明显。
使用特定的应用计算加速器来发展越来越具有广泛的前景,以及更好的每瓦性能。与为应用程序加速而建立的GPU相比,FPGA平台可用的内存带宽发展迅猛,例如,Al在他们的调查论文中描述了未来利用FPGA加速内存数据库的方法。
典型的加速器近内存计算体系结构中,CPU、FPGA或ASIC用作与内存本身分开的处理单元。主流采用近内存计算的一个特别挑战是从加速器对主机进程的虚拟内存进行高效的缓存一致访问。新兴的互连标准,如CAPI/OpenCAPI 和CXL通过提供缓存一致性,促进CPU和计算内存之间的数据交换。
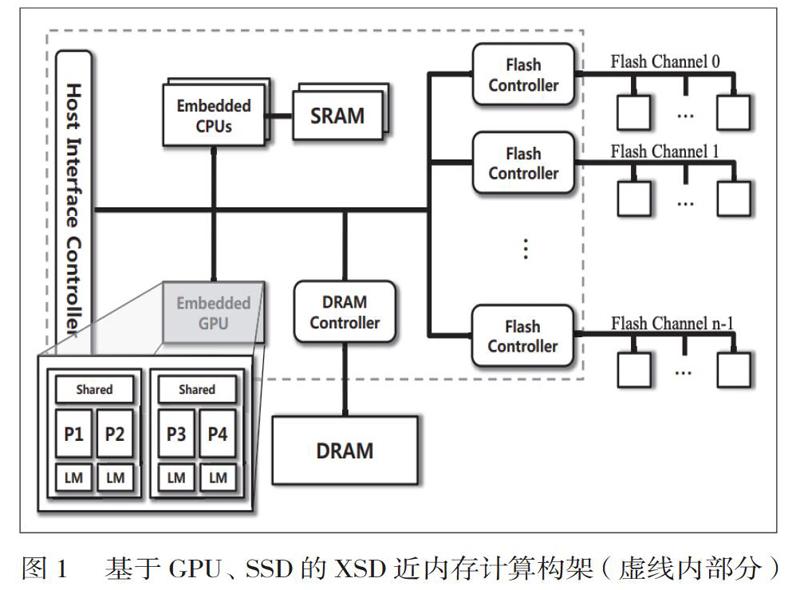
1.以传统的GPU(图形处理单元)作为加速单元的近内存计算研究方面,以Cho等人提出了一种集成 GPU 的新 SSD 架构XSD,XSD基于 MapReduce 框架提供的 API 集,允许用户在应用程序中调动并行运算,并利用嵌入式 GPU 提供的并行运算算力。同时,为了更好的性能和利用率,该框架也优化运算策略,以克服 SSD 架构中的缺点的影响。
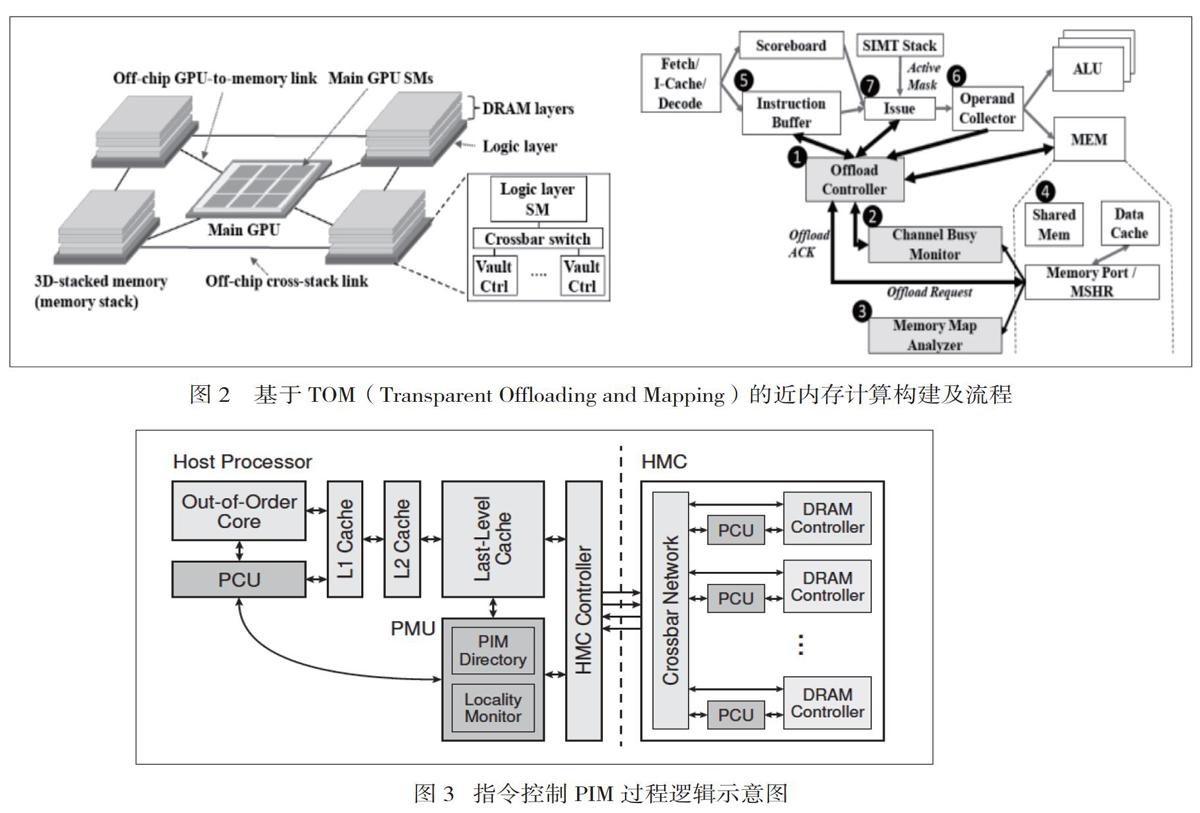
Hsieh等人提出了通过透明的CPU运算卸载和对应GPU运算映射的一种近内存构架,首先它根据自动标识代码卸载CPU运算到逻辑层的GPU。其次,通过软硬协作机制,实现预测卸载代码将访问的内存保留在内存堆栈中,以最大限度地减少运算带宽消耗,从而实现近内存计算。
2.通过CPU优化/运算构架等实现对数据流控制也是近内存计算的方向之一,在此方面学术上研究非常活跃。其中以Kang等人提出了通过隔离不同的近内存计算设备内的数据流来保证低能耗、高并行性、低主机内存占用率和更好的近内存计算性能。Seshadri等人]提出的允许程序员增强和扩展 SSD 的Willow构架,在其上运行的 SSD 应用程序为应用程序提供对 SSD 内容的低延迟、高带宽访问,同时减少 IO 处理在主机处理器上设置的负载。
3.在特定于应用程序的加速器(Application specific accelerator 简称ACC)来实现近内存计算方面,Ahn等人使用支持计算的内存命令实现简单的内存计算,并使用专用指令来调用内存中计算(图3)。这些操作与现有编程模型、缓存一致性协议和虚拟内存机制进行互操作,无需修改。同时,该研究还引入了一个简单的硬件结构,用于监视启用 PIM 的指令在运行时访问的数据位置,以便当指令判断当可以从在较大缓存中受益时,在主机处理器(而不是在内存中)自适应地执行指令。Gu等人提出了Biscuit,一个新的近数据处理框架,专为现代固态驱动器。t 允许程序员编写数据密集型应用程序,以分布式但无缝的方式在主机系统和存储系统上运行。为了提供高级编程模型,Biscuit运算构架,该构架以数据流的概念为构建,数据处理任务通过类型端口和数据排序端口进行通信。Biscuit实际部署在后端,因此不区分在主机系统和存储系统上运行的任务,因此具有通用性等理想特征。
4.以FPGA为加速单元的近内存计算研究,Jun等人提出了基于部署在FPGA上的持久性内存实现近内存计算的模型,Istv ?an等人提出了Caribou,一种基于TCP/IP的近内存计算架构。
参考文献
[1] J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing,” in 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), June 2015, pp. 105–117.
[2] P. C. Santos, G. F. Oliveira, D. G. Tom?e, M. A. Alves, E. C. Almeida, and L. Carro, “Operand Size Reconfiguration for Big Data Processing in Memory,” in Proceedings of the Conference on Design, Automation & Test in Europe. European Design and Automation Association, 2017, pp. 710–715.
赵晓菲(1987.10-),女,汉族,河北衡水人,研究生,高职教师,研究方向:内存计算
猜你喜欢 数据传输程序 给Windows添加程序快速切换栏电脑爱好者(2020年6期)2020-05-26简化化学平衡移动教学程序探索福建基础教育研究(2019年1期)2019-05-28USPTO修改PTAB《无效程序权利要求解释标准》中国知识产权(2018年11期)2018-11-29“程序猿”的生活什么样瞭望东方周刊(2017年42期)2017-12-05一种工业无线自适应退避竞争接入方法的研究现代电子技术(2017年19期)2017-10-12面向照明终端芯片程序的无线远程升级研究与应用软件导刊(2017年4期)2017-06-20一种基于LEACH协议的改进路由算法科技资讯(2016年34期)2017-04-21英国与欧盟正式启动“离婚”程序程序环球时报(2017-03-30)2017-03-30趋势or噱头?新潮电子(2017年2期)2017-03-07数据信息于无线传输之下的采集和控制科学家(2015年10期)2015-12-26



