辛雨璇 王晓东


摘 要:基于文本挖掘技术对电影评论进行深层数据分析.爬取电影网站短评,利用TF-IDF进行高频词可视化,对评论进行情感倾向分析.利用贝叶斯分类器将电影短评分为好评集和差评集,得出好评与差评集的主题词概率,找出影评大数据背后隐含的深层信息.
关键词:电影评论;情感分析;机器学习;LDA
[中图分类号]TP391.1 [文献标志码]A
Research on Sentiment Analysis of MovieReviews based on Text Mining
XIN Yuxuan,WANG Xiaodong
(School of Computer and Information Engineering,Mudanjiang Normal University,Mudanjiang 157011,China)
Abstract:Based on text mining technology,deep data analysis of movie reviews.Crawl short reviews of movie websites,use TF-IDF to visualize high-frequency words,and analyze the sentiment tendency of reviews.The Bayesian classifier is used to score short movies into favorable and negative review sets,and the probabilities of the subject words of the favorable and negative reviews are obtained,and the deep information behind the big data of film reviews is found.
Key words:movie reviews;sentiment analysis;machine learning;LDA
电影评论中隐含着关于电影真实评价的重要信息,这为电影业的进步提供了大众的评审意见.互联网上电影的观影者通常会写下对电影的真实感受,其他观影者通过查看电影评论了解该电影,并选择是否观看.随着影评的增多和信息的更迭,评论区数据通过Ajax动态加载,页面最多显示20余条评论信息,其他观影者仅能查看有限的评论数据,无法整体把握评论风向.笔者利用文本挖掘技术对电影网站短评进行爬取,利用机器学习算法实现对电影评论的情感分析,找出影评大数据背后隐含的深层信息,实现客观整体评价电影.
1 研究框架和数据采集清洗
1.1 研究框架
爬取某电影的评论数据,对评论文本进行预处理:数据清洗、降噪及文本分词.一是描述性分析,通过计算高频词汇,反映影评的评论热点.二是情感分析,将评论文本向量化;采用有监督学习的朴素贝叶斯分类方法,找到好评和差评集合;用LDA主题模型分别对好评和差评集进行分析,找到最大概率主题词;结合描述性分析和情感分析结果找到海量大数据背景下有参考价值的评论信息.
1.2 数据来源
收集工作使用两个爬虫路线[1]:一是根据用户输入的关键字抓取与关键字相关的電影信息,二是有针对性抓取选定电影的影评数据.爬虫的起点为初始URL,根据规则生成URL队列进行循环爬取,使用正则表达式解析网页内容,保存解析数据.首先,网站地址遵循关键词+偏移量的组合规则,根据关键词获得相关的电影,根据偏移量实现页面的翻页处理.其次,对网页结构进行分析.网站评论存在页面的特定区域,找到数据接口后,将数据以数据字典形式存储.每条数据内容5个维度:用户名称、所在城市、评论内容、电影评分以及评论的时间.
1.3 数据预处理
数据的预处理去除不完整的、不一致的数据,排除低质量的数据.如每条数据内容5个维度,单个数据遗漏一个或者多个既做去除处理.读取爬取数据信息,根据属性切片、筛选,将筛选后的属性值存入新的字典中汇总.本文采用jieba分词法对评论内容进行中文分词,将评论语句分为单独词汇.评论中的语气词出现频率很高,没有实际意义,对此类词语进行过滤.
2 评论文本描述性分析
2.1 基于TF-IDF计算高频词
统计一元和二元词频确定高频词汇.利用TF-IDF[2]对电影评论分词进行一元和二元计数得到高频词汇top20及权重,见表1.
TF-IDE=Ni,j∑kNi,jlog|D|1+|{j:Tj∈Dj}|.(1)
TF是词频,IDE为逆向文件频率,用于衡量出现的普遍程度,TF-IDE为两者乘积.式(1)中,Ni,j表示单词在文件D中出现的次数,∑kNi,j表示文件D中词条的总和,D语库中总文档数,|{j:Tj∈Dj}|表示包含词条T的总文档数.
2.2 评论描述可视化
基于Pyecharts库实现电影评论描述性可视化.以《复仇者联盟4》为例,饼状图可以直观反映评分星级占比(图1),词云图可以直观地突出文本数据中频率较高的关键词,形成“关键词的渲染”(图2).
3 电影评论情感倾向分析
电影评论文本的描述性分析能够在一定程度上对电影评价进行描述,但不能理解评论背后所表达的情感倾向.为了理解电影评论文本的深层语义,需要对电影评论进行情感分析.利用机器学习算法判断评论所表达的情感为正面还是负面,尝试找到评论背后议论的主题.
3.1 评论文字向量化表示
采用Word2vec技术[3]将文本词转换为词向量,采用CBOW模型,利用上下文信息wt-2,wt-1,wt+1,wt+2预测.输入层输入上下文的词向量,输出层计算出概率最高的词向量,模型如图3所示.利用python的Gensim包进行词向量提取.
3.2 基于朴素贝叶斯情感倾向分类
朴素贝叶斯可应用于向量化后的分类并取得较好的效果.[4]
其中,p(cj)为cj的先验概率,为某一类别占所有类别的比例;p(xi|cj)为后验概率,为某一类别特征向量在第n个维度下的特征向量xi出现的次数q与样本Q的比例.将电影评论分为两类,即正面评价和负面评价两类.正面评价用1,负面评价用0.用朴素贝叶斯分类收集标注好的词语作为训练集或进行二次人工标注.
统计实际数据,评价分类效果.笔者从网络上搜集到对该电影的正面评论数据2 012条,负面评论1 200条,作为训练集.实验结果表明,正面评价913条,占比76%;负面评价287条,占比23%.正面评价中,正确分类823条,错误分类90条.负面评价中,正确分类259条,错误分类38条.根据混淆矩阵计算[5],准确率为90%,精准率95%,召回率90%,平衡点92%.由于对测试语句的评价指标良好.本文用训练后的分类器对电影评论进行分类,得到正面和负面两个分类文档:“好评集.txt”和“差评集.txt”.
3.3 基于LDA的主题分析
3.3.1 利用LDA模型[6]计算围绕主题的关键词概率
(1)输入文档集W,对文档集的文档m确定其Nm;
(2)从多项式分布QM中取样生成文档m的第n个主题词zm;
(3)从Direchlet分布的k中取样生成主题词zm的词语分布;
(4)从词语的多项式分布Gm中采样得到最终的主题词;
(5)参数的估计采用Gibbs采样.
概率值计算公式:
p(w/α,β)=∫p(θ/α)∏nn=1∑zp(zn|θ)p(wn|zmβ)dθ.(5)
选取最大概率词作为主题词,通过统计词频对参数进行评估——下一个词主题条件概率的计算.
3.3.2 实验结果分析
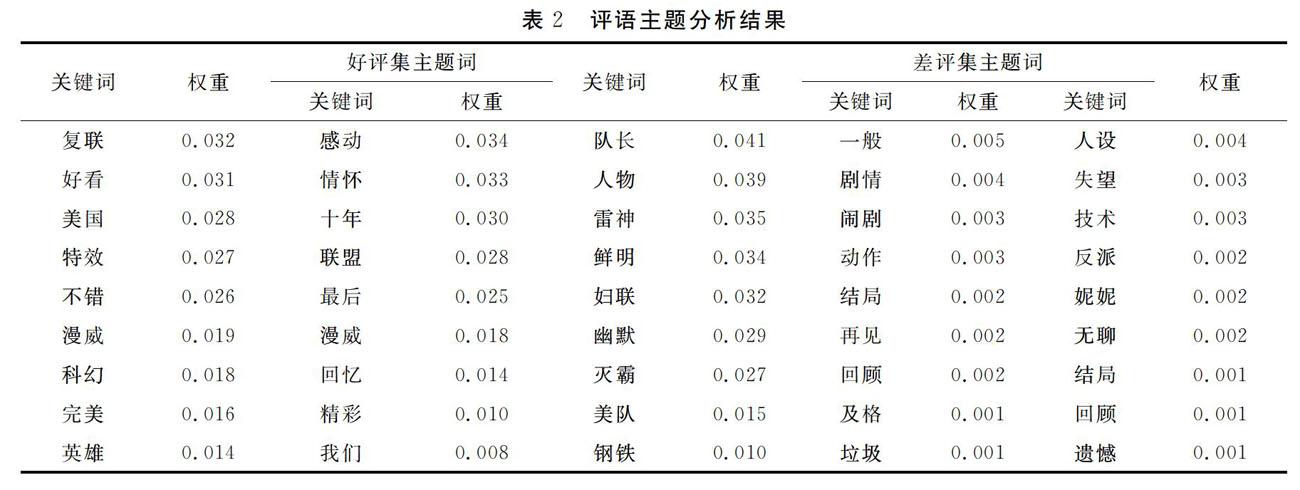
对好评集和差评集进行LDA主题分析.设置Gibbs抽样迭代次数为1 000.好评集的主题K取值分别为5,25,125;差评集的主题K取值为5,20,80;根据不同的主题数分别进行SC分析提取主题.好评主题数为125,差评主题数为50,详见表2.结果显示,该电影正面评论较多,观影者对电影总体满意.正面评论的主题词推测结果显示,好看和吸引观影者的地方在于特效和英雄,给观影者印象最深的部分是特效、英雄背后的情怀和满满的回忆.观影者还关注电影里面的英雄人物,例如队长、雷神等人物的塑造.负面评论主题词推测结果显示,部分观影者认为该电影一般.从主题词来看,剧情一般,缺少起伏,过多回顾,动作制作也一般.观影者对于结局和反派都有不满意,对于英雄的人设有崩塌,对反派也较为失望.
4 总结
本文将文本挖掘技术和机器学习算法运用到电影评论分析上,通过描述性分析和情感倾向分析两个层面试图找到用户评论背后隐藏的有用信息.在描述性分析上采用计算高频词概率并生成图云的方式,直观可视化表达.在情感分析层面将评论文本向量化,利用朴素贝叶斯分类法分类,找到高概率主题词,分析指定电影的优缺点,进行深层主题挖掘.在大数据背景下对观影者评论进行深层分析,有利于客观整体评价电影,有利于反映观影者真实感受,有利于其他观影者对是否观看该电影进行决策,有一定的实践意义.
参考文献
[1]杨治秋,李子龙.早期探测与数据分析的智能网络主题搜索[J].牡丹江师范学院学报:自然科学版,2010(2):8-10.
[2]SALTON G,BUCKLEY C.Term-weighting approaches inautomatic text retrieval[J].information processing&man-agement,Elsevier,1988,24(5):513-523.
[3]Yoshua Bengio,Rejean Ducharme,Pascal Vincent,and Christian Jauvin.A neural probabilistic language model[J].Journal of Machine Learning Research(JMLR),2003(3):1137-1155.
[4]CHEN X,QIU X,ZHU C,et al.Gated recursive neural network for Chinese word segment ation[C]//Proceedings of the 53rd annual meet the association for computational linguistics and the 7th international joint conference on natural language processing,2015:1744-1753.
[5]張丹.用线性组合模型分析软件可靠性数据[J].牡丹江师范学院学报:自然科学版,2007(4):9-11.
[6]Blei D M,Ng Andrew Y,Jordan,et al.Latent dirichlet allocation[J].Journal of machine Learning research,2003,3(Jan):993-1022.
编辑:琳莉
收稿日期:2020-10-28
基金项目:黑龙江自然科学基金项目(F2016039);黑龙江省教育厅科学研究项目(1355TD002)
作者简介:辛雨璇(1988-),女,山东肥城人.助教,硕士,主要从事大数据与人工智能研究;王晓东(1971),男,山东平度人.教授,博士,硕士生导师,主要从事定性空间推理和数据分析研究.
猜你喜欢 情感分析机器学习 基于追加评论的情感分析研究软件导刊(2019年11期)2019-12-12基于GLU-CNN和Attention-BiLSTM的神经网络情感倾向性分析软件(2019年7期)2019-10-08融合情感分析的中小企业信用风险评估研究中国管理信息化(2019年7期)2019-05-23基于词典与规则的文本情感分析电脑知识与技术(2018年26期)2018-12-18基于大数据技术的网络异常行为分析监测系统电子技术与软件工程(2017年24期)2018-01-17浅谈汽车无人驾驶技术科技资讯(2017年27期)2017-11-24机器学习在大视频运维中的应用中兴通讯技术(2017年4期)2017-09-07基于词典扩充的电力客服工单情感倾向性分析现代电子技术(2017年11期)2017-06-12机器学习技术在民航安全管理中的应用探析科技创新与应用(2017年12期)2017-05-08基于LDA模型的文本分类与观点挖掘电子技术与软件工程(2017年4期)2017-03-27



